风险(Risk)
样本数据 (Samples)
$$S = {\mathbf{z}_1, \mathbf{z}_2, \ldots, \mathbf{z}_n} \quad$$ 这是对我们用来训练模型的“数据集”的数学定义。
$S$ (Sample Set): 代表我们手头拥有的训练数据集,公式 (1) 表示这个集合包含了 $n$ 个数据点。
$\mathbf{z}_i = (\mathbf{x}_i, y_i)$: 代表数据集中的第 $i$ 个样本。在监督学习中,每个样本通常是一个键值对:$\mathbf{x}_i$ 是输入特征向量(比如图片的像素),$y_i$ 是对应的真实标签(比如图片的类别)。
独立同分布 (independent and identical draws, 缩写为 i.i.d.): 这是一个极其重要的假设。它假定这 $n$ 个样本都是相互独立地从同一个隐藏的、未知的真实数据分布 $\mathbb{P}$ 中抽取出来的。我们在现实中只能拿到有限的样本集 $S$,但我们真正关心的是那个产生这些数据的背后规律 $\mathbb{P}$。
损失函数 (Loss Function)
$$f(\mathbf{w}; \mathbf{z}) = \ell(h_\mathbf{w}(\mathbf{x}), y),$$ where $\ell: \mathbb{R} \times \mathbb{R} \mapsto \mathbb{R}+$._
损失函数用于量化“模型在单个样本上预测错得有多离谱”。
$\mathbf{w}$: 代表模型的参数集合(例如神经网络中的权重)。确定了 $\mathbf{w}$,就确定了一个具体的模型。
$h_\mathbf{w}(\mathbf{x})$: 假设函数(Hypothesis)。它表示给定输入 $\mathbf{x}$ 时,参数为 $\mathbf{w}$ 的模型给出的预测值。
$\ell$ (基础损失函数): 它的映射关系是 $\ell: \mathbb{R} \times \mathbb{R} \mapsto \mathbb{R}+$。意思是它接收两个实数(一个是预测值 $h\mathbf{w}(\mathbf{x})$,一个是真实标签 $y$),经过计算后输出一个非负实数($\mathbb{R}_+$ 代表非负实数集)。输出的值越大,说明预测与真实结果偏差越大。常见的 $\ell$ 包括平方损失 (MSE) 或交叉熵损失。
$f(\mathbf{w}; \mathbf{z})$: 这是一个简化的记号,将基础损失 $\ell$ 封装了起来。它直接表示“参数为 $\mathbf{w}$ 的模型,在具体样本 $\mathbf{z}=(\mathbf{x}, y)$ 上产生的误差大小”。
经验风险与总体风险 (Empirical and Population Risk)
$$F_S(\mathbf{w}) = \frac{1}{n}\sum_{i=1}^n f(\mathbf{w}; \mathbf{z}i) \quad \text{and} \quad F(\mathbf{w}) = \mathbb{E}\mathbf{z}[f(\mathbf{w}; \mathbf{z})]$$
$F_S(\mathbf{w})$ - 经验风险 (Empirical Risk): * 公式解释:它等于模型 $\mathbf{w}$ 在包含 $n$ 个样本的训练集 $S$ 上每个样本损失的算术平均值。
- 意义:这是我们在实际写代码训练模型时,可以真真切切算出来的误差。机器学习的优化算法(比如梯度下降)往往就是在这个指标上进行最小化。
$F(\mathbf{w})$ - 总体风险 / 期望风险 (Population Risk): * 公式解释:它等于模型 $\mathbf{w}$ 在整个真实数据分布 $\mathbb{P}$ 上的期望损失(用期望算子 $\mathbb{E}_\mathbf{z}$ 表示)。
我们使用 $A$ 代表某一种特定的机器学习算法(例如经验风险最小化 ERM,或者随机梯度下降 SGD)。
那么 $A(S)$ 强调了最终训练出来的模型并不是一个固定的常数,而是一个依赖于训练数据集 $S$ 的随机变量。如果我们要重新采样得到另一个不同的训练集 $S’$,同一种算法 $A$ 训练出来的模型 $A(S’)$ 可能就会不一样。后续分析算法的“稳定性 (Stability)”时,就是研究当 $S$ 发生微小变化时,$A(S)$ 的变化幅度。
误差分解 (Error Decomposition)
超额风险 (Excess Risk) 与最优模型
输出模型 $A(S)$ 相对于最优模型 $\mathbf{w}^$ 的表现差异,可以通过超额风险 $F(A(S)) - F(\mathbf{w}^)$ 来量化。其中: $$\mathbf{w}^* = \arg\min_{\mathbf{w} \in \mathcal{W}} F(\mathbf{w}) \text{ 是最优模型。}$$
$A(S)$:表示我们的算法 $A$ 在具体训练集 $S$ 上跑出来的最终模型。
$\mathbf{w}^*$:这是在假设空间 $\mathcal{W}$(比如所有可能参数的神经网络)中,理论上绝对最好的模型。它最小化的是总体风险 $F(\mathbf{w})$(即在真实数据分布上的期望损失)。因为真实分布永远是未知的,所以 $\mathbf{w}^*$ 在现实中求不出来,它相当于我们心中的“完美参考线”。
超额风险 ($F(A(S)) - F(\mathbf{w}^*)$):这是衡量我们训练出的模型 $A(S)$ 到底有多好的终极指标。它等于“我们实际模型在未知总体数据上的误差”减去“理论最优模型在未知总体数据上的误差”。这个差值越小,说明我们的模型越接近完美。
误差分解的核心等式 (The Core Decomposition)
我们将超额风险分解为:
$$F(A(S)) - F(\mathbf{w}^) = (F(A(S)) - F_S(A(S))) + (F_S(A(S)) - F_S(\mathbf{w}^)) + (F_S(\mathbf{w}^) - F(\mathbf{w}^))$$
通过“加一项、减一项”的数学代数技巧,将一个我们无法直接计算的超额风险,巧妙地拆分成了三个具有明确物理意义的部分:
第一项:$F(A(S)) - F_S(A(S))$
- 物理意义:这部分被称为泛化误差界限 (Generalization Gap) 或估计误差的一部分。它衡量了模型在真实总体上的表现 ($F$) 与在训练集上的表现 ($F_S$) 之间的差距。如果这一项很大,说明模型在训练集上表现极好,但到了真实测试中就拉垮了,也就是发生了过拟合 (Overfitting)。
第二项:$F_S(A(S)) - F_S(\mathbf{w}^*)$
物理意义:这部分被称为优化误差 (Optimization Error)。它衡量了我们的算法 $A$ 在训练集 $S$ 上,到底有没有真的找到经验风险的最小值。
补充说明:如果你的算法是完美的经验风险最小化器 (ERM),也就是说 $A(S)$ 绝对最小化了 $F_S$,那么这一项必然 $\le 0$。但在深度学习中,由于优化的目标函数是非凸的,我们用 SGD 往往找不到全局最优,所以这一项经常被单独拿出来分析优化算法的收敛性。
第三项:$F_S(\mathbf{w}^) - F(\mathbf{w}^)$
- 物理意义:这部分是理论最优模型 $\mathbf{w}^*$ 在训练集上的经验误差与其真实期望误差之间的差。这一项与你的算法 $A$ 毫无关系,纯粹是由有限数据的随机采样波动引起的。
对最优模型 $\mathbf{w}^*$ 的误差分析
令 $\xi_i = f(\mathbf{w}^; \mathbf{z}_i)$,我们有: $$F_S(\mathbf{w}^) - F(\mathbf{w}^) = \frac{1}{n}\sum_{i=1}^n f(\mathbf{w}^; \mathbf{z}i) - \mathbb{E}{\mathbf{z}}[f(\mathbf{w}^*; \mathbf{z})] = \frac{1}{n}\sum_{i=1}^n [\xi_i - \mathbb{E}[\xi_i]]$$ 这一步是在对上面分解出的第三项进行化简,以便后续放缩:
我们把最优模型在第 $i$ 个具体样本上的损失简写为一个变量 $\xi_i$。
最关键的一点是:因为 $\mathbf{w}^*$ 是一个固定的模型(它是由真实概率分布决定的“上帝视角”模型,不依赖于你抽到的具体数据集 $S$),所以所有的 $\xi_i$ 都是独立同分布 (i.i.d.) 的随机变量。
化简到最后一步 $\frac{1}{n}\sum [\xi_i - \mathbb{E}[\xi_i]]$ 时,它就变成了一个非常标准的“独立随机变量的样本均值减去其真实期望”的数学形式。在后续的证明中,可以直接套用统计学中极其成熟的集中不等式(比如 Hoeffding 不等式)来证明:随着样本量 $n$ 的增大,这一项以极高的概率趋近于 0。
对算法输出模型 $A(S)$ 的误差分析
我们还有: $$F(A(S)) - F_S(A(S)) = \frac{1}{n}\sum_{i=1}^n \left( \mathbb{E}_{\mathbf{z}}[f(A(S); \mathbf{z})] - f(A(S); \mathbf{z}_i) \right)$$ 这一步是对分解出的第一项进行展开:
表面上看,这个公式和上面第三部分非常相似,也是“期望风险减去经验风险”。
核心陷阱:千万要注意,这里的模型 $A(S)$ 是依赖于训练集 $S = {\mathbf{z}_1, \dots, \mathbf{z}_n}$ 的!模型是你用这些数据训练出来的,所以 $A(S)$ 和样本 $\mathbf{z}_i$ 之间存在强相关性。
因为这种数据依赖性的存在,我们绝对不能像第三部分那样,直接套用简单的集中不等式。为了在数学上约束并控制这一项,统计学习理论界主要发展出了两条路:
一致偏差 (Uniform Deviation):不去管具体的 $A(S)$,而是直接求整个假设空间中所有可能模型的最坏情况(取上确界 supremum),从而引入 Rademacher 复杂度或 VC 维来消除数据依赖。
算法稳定性 (Algorithmic Stability):通过证明算法本身的鲁棒性(即证明“如果改变训练集中的某一个样本,算法输出的模型变化非常小”)来控制这一项的上限。
一致偏差 (Uniform Deviation)
$A(S)$ 依赖于训练集 $S$。我们通过在整个假设空间 $\mathbf{w} \in \mathcal{W}$ 上取上确界(supremum)来处理这种依赖性。
我们想评估的是某个具体模型 $A(S)$ 在真实世界和训练集上的表现差异。
既然 $A(S)$ 总是和 $S$ 纠缠不清,理论家们想出了一个极其粗暴但也极其有效的降维打击方案:我们干脆不看具体的 $A(S)$ 了,我们直接看整个模型池子里“最坏的情况”。
$\mathcal{W}$ 代表假设空间(Hypothesis Space),也就是你设定的所有可能模型的集合(比如所有参数不大于 1 的线性模型)。无论你的算法 $A$ 怎么折腾,它最终输出的模型 $A(S)$ 必然是 $\mathcal{W}$ 里面的一个元素。
$$F(A(S)) - F_S(A(S)) \le \sup_{\mathbf{w} \in \mathcal{W}} \left[ \frac{1}{n} \sum_{i=1}^n \left( \mathbb{E}{\mathbf{z}}[f(\mathbf{w}; \mathbf{z})] - f(\mathbf{w}; \mathbf{z}i) \right) \right]$$ $$= \sup{\mathbf{w} \in \mathcal{W}} \big[ F(\mathbf{w}) - F_S(\mathbf{w}) \big]$$ $A(S)$ 只是集合 $\mathcal{W}$ 中的某一个特定参数,那么它对应的泛化差距,必然小于或等于集合 $\mathcal{W}$ 中所有可能参数所能产生的最大泛化差距。$\sup{\mathbf{w} \in \mathcal{W}}$ 可以理解为在连续空间里取最大值 (max)。
$\mathbb{E}_{\mathbf{z}}[f(\mathbf{w}; \mathbf{z})]$ 就是总体风险 $F(\mathbf{w})$;而 $\frac{1}{n} \sum f(\mathbf{w}; \mathbf{z}_i)$ 就是经验风险 $F_S(\mathbf{w})$。所以括号里其实就是 $F(\mathbf{w}) - F_S(\mathbf{w})$。
经过这一步放缩,不等式右边的 $\mathbf{w}$ 变成了一个自由变量(Dummy Variable)。它代表空间里的任意固定模型,不再是被算法绑定、随数据集 $S$ 波动的随机变量了。我们成功地把针对具体算法的分析,转化为了针对整个函数空间 $\mathcal{W}$ 性质的分析。
现在只要整个空间里最坏的那个模型不发生严重的过拟合,我们找出的特定模型 $A(S)$ 就一定安全。
既然我们现在的目标变成了去界定这个上确界 $\sup_{\mathbf{w} \in \mathcal{W}} \big[ F(\mathbf{w}) - F_S(\mathbf{w}) \big]$,那么现在的思路是:
使用集中不等式 (concentration inequality) 将 $\sup_{\mathbf{w} \in \mathcal{W}} \big[ F(\mathbf{w}) - F_S(\mathbf{w}) \big]$ 与它的期望 $\mathbb{E} \sup_{\mathbf{w} \in \mathcal{W}} \big[ F(\mathbf{w}) - F_S(\mathbf{w}) \big]$ 联系起来。
尽管我们解除了 $\mathbf{w}$ 对数据的依赖,但经验风险 $F_S(\mathbf{w})$ 本身还是依赖于随机抽样的训练集 $S$ 的。因此,带有上确界的这一大串 $\sup [\cdots]$ 依然是一个随机变量。
统计学告诉我们,如果一个随机变量受到很多独立样本的影响,那么它的取值会高度集中在它的数学期望 (Expectation, $\mathbb{E}$) 附近。
在实际证明中(比如后续用到的 McDiarmid 不等式),我们会证明:这个上确界以极高的概率($1-\delta$)不会偏离它的期望值太多。
通过函数空间的复杂度(例如 Rademacher 复杂度)来控制期望项 $\mathbb{E} \sup_{\mathbf{w} \in \mathcal{W}} \big[ F(\mathbf{w}) - F_S(\mathbf{w}) \big]$。
经过第一步,我们把问题转化为了如何求一个纯粹的期望值 $\mathbb{E} \sup [\cdots]$ 的上界。
这个期望值衡量的是什么?它衡量的是你的模型空间 $\mathcal{W}$ 拟合随机噪声的能力。
想象一下,如果你的模型空间极其庞大复杂(比如一个拥有万亿参数的超大神经网络),它甚至可以把完全随机的标签都完美拟合(让经验风险 $F_S$ 降到 0),此时真实的风险 $F$ 依然很高。这种情况下,$\sup [F - F_S]$ 的期望值就会非常大。
反之,如果模型空间很简单(比如只能画直线的线性分类器),它就无法强行拟合噪声,这个期望值就会很小。
为了在数学上精确量化这种“模型空间的复杂度”,理论家们引入了 Rademacher 复杂度 (Rademacher complexity) 或者 VC 维。一旦算出了特定模型的 Rademacher 复杂度,将其代入,我们就彻底完成了泛化误差的推导。
集中不等式 (Concentration Inequality)
马尔可夫不等式 (Markov’s Inequality)
马尔可夫不等式的条件最弱,结论也最保守。
前提条件:随机变量 $X$ 必须是非负的,并且 $a > 0$ 。这是它唯一的要求。
核心公式: $$\mathbb{P}(X \ge a) \le \frac{\mathbb{E}[X]}{a}$$
详细解释:随机变量 $X$ 大于或等于某个正数 $a$ 的概率,不会超过它的数学期望 $\mathbb{E}[X]$ 除以 $a$ 。
直观理解:假设一个班级的平均分(期望 $\mathbb{E}[X]$)是 50 分,且分数不能是负数(非负条件)。那么班里考到 100 分及以上(设 $a = 100$)的人数比例,最多不能超过 $50 / 100 = 50%$。如果超过了 50%,因为其他人最低也是 0 分,全班平均分就一定会超过 50 分,这与已知矛盾。
在 ML 中的局限:因为马尔可夫不等式只利用了“期望”这一个信息,没有考虑数据的分布形状,所以它给出的上界通常非常松散(不够紧凑)。
切比雪夫不等式 (Chebyshev’s Inequality)
切比雪夫不等式比马尔可夫不等式更进了一步,因为它引入了方差 (Variance) 的信息。
前提条件:随机变量 $X$ 具有明确的均值 $\mu$ 和方差 $\sigma^2$ 。注意,这里不再要求 $X$ 必须是非负的了。
核心公式: $$\mathbb{P}(|X - \mu| \ge a) \le \frac{\sigma^2}{a^2}$$
详细解释:对于任意正数 $a > 0$,随机变量 $X$ 偏离其均值 $\mu$ 的距离大于或等于 $a$ 的概率,其上限为方差 $\sigma^2$ 除以 $a^2$ 。
直观理解:方差 $\sigma^2$ 衡量的是数据的“波动程度”。这个公式告诉我们,如果一个随机变量的方差很小,那么它“跑偏”(偏离均值很远)的概率就会以平方的级别极速下降。
证明套路:切比雪夫不等式完全可以通过马尔可夫不等式推导出来。我们在作业和考试中经常会用到这种构造技巧:
令一个新的随机变量 $Y = (X - \mu)^2$。显然 $Y$ 是非负的。
那么 $\mathbb{P}(|X - \mu| \ge a)$ 其实等价于 $\mathbb{P}(Y \ge a^2)$。
直接对 $Y$ 套用马尔可夫不等式:$\mathbb{P}(Y \ge a^2) \le \frac{\mathbb{E}[Y]}{a^2}$。
因为 $\mathbb{E}[Y] = \mathbb{E}[(X - \mu)^2]$ 就是方差 $\sigma^2$,代入进去,切比雪夫不等式就得证了。
有界差分假设 (Bounded difference assumption)
我们称一个函数 $g : \mathcal{Z}^n \mapsto \mathbb{R}$ 满足有界差分假设,如果存在常数 $c_1, \dots, c_n > 0$,使得: $$\sup_{\mathbf{z}_1, \dots, \mathbf{z}_n, \mathbf{z}_i’} |g(\mathbf{z}_1, \dots, \mathbf{z}_n) - g(\mathbf{z}1, \dots, \mathbf{z}{i-1}, \mathbf{z}i’, \mathbf{z}{i+1}, \dots, \mathbf{z}_n)| \le c_i, \quad \forall i \in [n].$$
$g : \mathcal{Z}^n \mapsto \mathbb{R}$:这是一个接收 $n$ 个样本作为输入,并输出一个实数的函数。在机器学习中,这个 $g$ 通常代表“在数据集上计算出来的某种经验指标”,比如经验风险 $F_S(\mathbf{w})$ 或者算法跑出来的损失。
替换单个样本:公式对比了两个几乎一模一样的数据集。前面的是原始数据集 $(\mathbf{z}_1, \dots, \mathbf{z}_n)$,后面的是把第 $i$ 个样本 $\mathbf{z}_i$ 偷偷换成了一个新样本 $\mathbf{z}_i’$,其他 $n-1$ 个样本完全保持不变。
$\sup$ (上确界) 与 $c_i$:这个条件要求,在最坏最极端的情况下(遍历所有可能的数据集组合,遍历所有可能的替换样本),仅仅替换第 $i$ 个位置的一个样本,导致函数 $g$ 的输出值的波动(绝对值),永远不能超过一个固定的常数 $c_i$。
直观理解(稳定性):你可以把它理解为函数的“抗干扰能力”或“稳定性”。如果一个函数满足有界差分条件,说明它对数据集中任何单一数据点的变化都是“迟钝”的。如果改变一个样本就能让输出结果翻天覆地,那它就不满足这个条件。
McDiarmid 不等式 (McDiarmid’s Inequality)
当一个函数被证明满足上述的“稳定性”后,我们可以直接套用 McDiarmid 不等式来给出极强的概率界限。
假设 $Z_1, \dots, Z_n$ 是独立的随机变量。如果函数 $g : \mathcal{Z}^n \mapsto \mathbb{R}$ 满足有界差分假设,那么至少以 $1 - \delta$ 的概率,我们有: $$g(Z_1, \dots, Z_n) \le \mathbb{E}Z[g(Z_1, \dots, Z_n)] + \left(\frac{\log(1/\delta)}{2} \sum{i=1}^n c_i^2\right)^{\frac{1}{2}}.$$
独立性前提:样本 $Z_1, \dots, Z_n$ 必须是相互独立的(在机器学习中,通常就是 i.i.d. 假设)。
不等式的含义:函数在具体数据集上的实际观测值 $g(Z_1, \dots, Z_n)$,极大概率($\ge 1 - \delta$)不会超过它的理论数学期望 $\mathbb{E}_Z[g]$ 加上一个“误差尾巴(Margin)”。
解剖误差尾巴 $\left(\frac{\log(1/\delta)}{2} \sum_{i=1}^n c_i^2\right)^{\frac{1}{2}}$:
$\delta$ (失败概率):如果我们想要 99% 的置信度,$\delta$ 就是 0.01。$\log(1/\delta)$ 表明,即使我们要求极高的确定性($\delta \to 0$),这个误差尾巴也只会以极慢的对数速度增长。
$\sum_{i=1}^n c_i^2$ (灵敏度累加):这是决定收敛速度的核心。在很多证明题(比如证明经验风险的集中)中,每个样本对平均值的贡献权重通常是 $1/n$。如果你能证明 $c_i = \mathcal{O}(1/n)$,那么 $\sum_{i=1}^n c_i^2 = n \cdot \mathcal{O}(1/n^2) = \mathcal{O}(1/n)$。开根号之后,整个误差项就是 $\mathcal{O}(1/\sqrt{n})$ 的级别。这意味着随着样本量 $n$ 的增大,实际观测值会以 $1/\sqrt{n}$ 的速率死死地逼近数学期望。
类似地,以下不等式同样至少以 $1 - \delta$ 的概率成立: $$\mathbb{E}Z[g(Z_1, \dots, Z_n)] \le g(Z_1, \dots, Z_n) + \left(\frac{\log(1/\delta)}{2} \sum{i=1}^n c_i^2\right)^{\frac{1}{2}}.$$ 在学习理论中,我们真正想要知道的往往是未知的期望(例如总体风险)。因为我们手头只有在训练集上算出来的实际值(例如经验风险),所以通常是利用这个公式,用已知算未知,从而宣称:“未知的期望风险,大概率不会超过我们算出来的经验风险加上这个误差界限”。
经验风险最小化 (Empirical Risk Minimization, ERM)
让我们考虑经验风险最小化算法
$$A(S) = \arg\min_{\mathbf{w} \in \mathcal{W}} F_S(\mathbf{w}).$$
这里的算法 $A$ 被具象化为了 ERM。
$\arg\min$:它的意思是,算法 $A(S)$ 会在整个假设空间 $\mathcal{W}$ 中进行地毯式搜索,只输出那个能让训练集经验风险 $F_S(\mathbf{w})$ 达到绝对最小值的参数。
这是理论上的完美情况。在现实训练深度神经网络时,由于局部最优的存在,我们很难找到真正的全局最小,但在这一节的理论分析中,我们假设这个算法是完美的,能直接锁定经验风险的全局最低点。
在这种情况下,我们有 $F_S(A(S)) - F_S(\mathbf{w}^*) \le 0$,因此不需要考虑优化误差,即:
$$F(A(S)) - F(\mathbf{w}^) \le (F(A(S)) - F_S(A(S))) + (F_S(\mathbf{w}^) - F(\mathbf{w}^*))$$
这里的原因是:
$\mathbf{w}^*$ 是在真实总体数据上表现最好的模型。
$A(S)$ 是在当前训练集 $S$ 上表现最好的模型(因为它是 ERM 算出来的)。
所以,如果在训练集 $S$ 这个主场上进行 PK,$A(S)$ 的训练误差 $F_S(A(S))$ 绝对不可能大于任何其他模型的训练误差,包括那个理论最优的 $\mathbf{w}^*$。
因此现在只剩下了两项:
一致偏差项:$F(A(S)) - F_S(A(S))$
最优模型的抽样误差项:$F_S(\mathbf{w}^) - F(\mathbf{w}^)$
利用集中不等式,我们证明至少以 $1 - \delta$ 的概率成立:
$$F(A(S)) - F(\mathbf{w}^*) \le \sqrt{2} n^{-\frac{1}{2}} \log^{\frac{1}{2}}(2/\delta) + \mathbb{E}\left[ \sup_{\mathbf{w} \in \mathcal{W}} \frac{1}{n} \sum_{i=1}^n \left( \mathbb{E}_{\mathbf{z}}[f(\mathbf{w}; \mathbf{z})] - f(\mathbf{w}; \mathbf{z}_i) \right) \right].$$
具体证明:
根据前面“Uniform Deviation”那一页的结论,项 1 被放缩为整个函数空间的上确界:
$$\sup_{\mathbf{w} \in \mathcal{W}} [F(\mathbf{w}) - F_S(\mathbf{w})]$$
由于经验风险 $F_S$ 依赖于随机抽样,我们对这个上确界套用 McDiarmid 不等式。为了保证最后总的失败概率不超过 $\delta$,我们要求这个不等式以 $1 - \delta/2$ 的概率成立(即失败概率为 $\delta/2$)。
代入 McDiarmid 公式:
$$\sup_{\mathbf{w} \in \mathcal{W}} [F(\mathbf{w}) - F_S(\mathbf{w})] \le \mathbb{E}\left[ \sup_{\mathbf{w} \in \mathcal{W}} [F(\mathbf{w}) - F_S(\mathbf{w})] \right] + \sqrt{\frac{\log(2/\delta)}{2n}}$$
注: 这里根号里分子原本是 $\log(1/失败概率)$,因为失败概率设定成了 $\delta/2$,所以变成了 $\log(2/\delta)$。
对于项 2,$\mathbf{w}^*$ 是一个固定的最优模型。我们同样对它套用 McDiarmid 不等式(或者 Hoeffding 不等式),并同样要求以 $1 - \delta/2$ 的概率成立:
$$F_S(\mathbf{w}^) - F(\mathbf{w}^) \le \mathbb{E}[F_S(\mathbf{w}^) - F(\mathbf{w}^)] + \sqrt{\frac{\log(2/\delta)}{2n}}$$
因为 $F_S(\mathbf{w}^)$ 的数学期望本身就是真正的总体风险 $F(\mathbf{w}^)$,所以 $\mathbb{E}[F_S(\mathbf{w}^) - F(\mathbf{w}^)] = 0$。
于是项 2 简化为: $$F_S(\mathbf{w}^) - F(\mathbf{w}^) \le 0 + \sqrt{\frac{\log(2/\delta)}{2n}}$$
现在,我们有两个高概率成立的不等式:
项 1 的界限成立的概率 $\ge 1 - \delta/2$
项 2 的界限成立的概率 $\ge 1 - \delta/2$
根据概率论中的联合界(Union Bound),这两个好事情同时发生的概率,至少是 $1 - (\delta/2 + \delta/2) = 1 - \delta$。
在同时成立的前提下,我们把第二步和第三步的结果加起来,代入第一步的起点:
$$F(A(S)) - F(\mathbf{w}^*) \le \mathbb{E}\left[ \sup_{\mathbf{w} \in \mathcal{W}} [F(\mathbf{w}) - F_S(\mathbf{w})] \right] + \sqrt{\frac{\log(2/\delta)}{2n}} + \sqrt{\frac{\log(2/\delta)}{2n}}$$
整理: $$= \sqrt{\frac{2\log(2/\delta)}{n}}$$
最后,把常数 $\sqrt{2}$、$n$ 的幂和对数的幂拆开写:
$$= \sqrt{2} \cdot n^{-\frac{1}{2}} \cdot \log^{\frac{1}{2}}(2/\delta)$$
再加上中间保留下来的期望值项 $\mathbb{E}[\sup \dots]$,就拼成了最终公式。
拉德马赫复杂度 (Rademacher Complexity)
现在我们将泛化误差上界的问题,转化为了求解整个假设空间中最坏情况的期望:$\mathbb{E} \left[ \sup_{\mathbf{w} \in \mathcal{W}} (F(\mathbf{w}) - F_S(\mathbf{w})) \right]$。现在我们的任务是将期望值,彻底转化为一个可以量化、可以计算的复杂度指标。
对称化引理 (Symmetrization Lemma)
我们需要控制这个难搞的期望项:
$$\mathbb{E} \left[ \sup_{\mathbf{w} \in \mathcal{W}} \frac{1}{n} \sum_{i=1}^n (\mathbb{E}_{\mathbf{z}}[f(\mathbf{w}; \mathbf{z})] - f(\mathbf{w}; \mathbf{z}_i)) \right]$$
痛点:公式里既有内部的 $\mathbb{E}$,又有外部的 $\mathbb{E}$,还有个恼人的 $\sup$ 挡在中间。
为了消掉内部的 $\mathbb{E}$,我们引入一组和原始样本 $S$ 独立同分布的新样本 $S’ = {\mathbf{z}_1’, \dots, \mathbf{z}_n’}$。
根据期望的定义:$\mathbb{E}{\mathbf{z}}[f(\mathbf{w}; \mathbf{z})] = \mathbb{E}{S’}[f(\mathbf{w}; \mathbf{z}i’)]$。因此我们引入这个幽灵样本,此时的公式变为: $$\mathbb{E}{S} \left[ \sup_{\mathbf{w} \in \mathcal{W}} \left( \mathbb{E}_{S’}\left[\frac{1}{n}\sum f(\mathbf{w}; \mathbf{z}_i’)\right] - \frac{1}{n}\sum f(\mathbf{w}; \mathbf{z}_i) \right) \right]$$
期望有一个基本性质:$\mathbb{E}[X] - C = \mathbb{E}[X - C]$。因此可以化为:
$$\mathbb{E}{S} \left[ \sup{\mathbf{w} \in \mathcal{W}} \color{red}{\mathbb{E}_{S’}} \left[ \frac{1}{n}\sum f(\mathbf{w}; \mathbf{z}_i’) - \frac{1}{n}\sum f(\mathbf{w}; \mathbf{z}_i) \right] \right]$$
现在我们需要把 $\color{red}{\mathbb{E}_{S’}}$ 挪到 $\sup$ 的外面,根据Jensen不等式有:
$$\sup_{\mathbf{w}} (\mathbb{E}{S’}[\dots]) \le \mathbb{E}{S’} (\sup_{\mathbf{w}} [\dots])$$
应用,把 $\mathbb{E}{S’}$ 提到 $\sup$ 外面: $$\le \mathbb{E}{S, S’} \left[ \sup_{\mathbf{w} \in \mathcal{W}} \frac{1}{n} \sum_{i=1}^n (f(\mathbf{w}; \mathbf{z}_i’) - f(\mathbf{w}; \mathbf{z}_i)) \right]$$
接着,我们引入 Rademacher 变量 (投硬币)
对称性原理:既然 $\mathbf{z}_i$ 和 $\mathbf{z}_i’$ 是一模一样的分布,那么 $(f(\mathbf{w}; \mathbf{z}_i’) - f(\mathbf{w}; \mathbf{z}_i))$ 这个差值是正还是负,概率应该是一样的。
引入 $\epsilon_i$:
$A$ 和 $B$ 是两个一模一样的独立正态分布,那么 $(A - B)$ 是什么分布?
答案是:它是一个完美对称的分布。$(A - B) = 5$ 的概率,和 $(A - B) = -5$ 的概率完全一样。
我们的 $f(\mathbf{w}; \mathbf{z}_i’)$ 和 $f(\mathbf{w}; \mathbf{z}_i)$ 就像是这里的 $A$ 和 $B$。所以它们的差值 $(f’ - f)$ 的分布是关于 0 对称的。
既然是对称的,我现在引入一个硬币 $\epsilon_i$:
正面(+1):我保留 $(f’ - f)$ 的值。
反面(-1):我把它变成 $-(f’ - f)$,也就是把它翻转过来。
因为 $(f’ - f)$ 本身就是左右对称的,你再怎么随机翻转它,整个概率分布依然岿然不动,它的数学期望完全不变!
我们引入随机变量 $\epsilon_i \in {+1, -1}$,且 $P(\epsilon_i = 1) = P(\epsilon_i = -1) = 1/2$。
即使在项前面乘以 $\epsilon_i$,它的分布保持不变: $$\mathbb{E}{S, S’, \epsilon} \left[ \sup{\mathbf{w} \in \mathcal{W}} \frac{1}{n} \sum_{i=1}^n \epsilon_i (f(\mathbf{w}; \mathbf{z}_i’) - f(\mathbf{w}; \mathbf{z}_i)) \right]$$
利用 $\sup(A + B) \le \sup A + \sup B$:
拆成两部分:$\mathbb{E} \left[ \sup \frac{1}{n} \sum \epsilon_i f(\mathbf{w}; \mathbf{z}_i’) \right] + \mathbb{E} \left[ \sup \frac{1}{n} \sum -\epsilon_i f(\mathbf{w}; \mathbf{z}_i) \right]$。
观察发现:由于 $\epsilon_i$ 和 $-\epsilon_i$ 分布一样,$S$ 和 $S’$ 分布也一样,这两项其实是完全相等的。
最终合体公式: $$\text{Original Term} \le \frac{2}{n} \mathbb{E}{S, \epsilon} \left[ \sup{\mathbf{w} \in \mathcal{W}} \sum_{i=1}^n \epsilon_i f(\mathbf{w}; \mathbf{z}_i) \right]$$ 这个最终形式非常直观:
$\sum \epsilon_i f(\mathbf{w}; \mathbf{z}_i)$ 可以看作是模型 $f$ 在拟合一组纯随机的噪声(即随机的 $\pm 1$)。
Rademacher 复杂度越高,说明这个模型空间 $\mathcal{W}$ 越强,强大到甚至能把随机噪声都拟合得很好。
结论:如果一个模型能拟合随机噪声,那它就很容易过拟合。所以泛化误差界限里,这一项必须作为代价加进去。
正式定义 (Definition)
令 $\epsilon_1, \dots, \epsilon_n$ 为独立的 Rademacher 变量(以相等的概率仅取 $\pm 1$ 的值)。
函数空间 $\mathcal{F}$ 在给定样本集 $S = {\mathbf{z}_i}$ 上的经验 Rademacher 复杂度 (Empirical Rademacher Complexity) 定义为:
$$\mathfrak{R}S(\mathcal{F}) := \mathbb{E}{\boldsymbol{\epsilon}} \left[ \sup_{f \in \mathcal{F}} \frac{1}{n} \sum_{i=1}^n \epsilon_i f(\mathbf{z}_i) \right]$$
$\epsilon_i$ (纯随机噪声):想象你抛硬币,正面就给第 $i$ 个样本打上 $+1$ 的标签,反面就打上 $-1$ 的标签。$\boldsymbol{\epsilon} = (\epsilon_1, \dots, \epsilon_n)$ 就是一串完全随机的噪声。
$f(\mathbf{z}_i)$:表示函数空间 $\mathcal{F}$ 中某一个特定的函数 $f$(相当于前面由参数 $\mathbf{w}$ 决定的网络模型)在样本 $\mathbf{z}_i$ 上的输出。
$\frac{1}{n} \sum_{i=1}^n \epsilon_i f(\mathbf{z}_i)$ (内积/相关性):你可以把它看作是模型输出向量与随机噪声向量的内积(再除以 $n$ 取平均)。如果模型输出的符号和这些完全随机抛硬币得出的符号 $\epsilon_i$ 高度一致,这个求和的值就会非常大。
$\sup_{f \in \mathcal{F}}$ (寻找最坏情况):这句话的意思是:“在你的整个函数库(比如所有可能的神经网络权重组合)里,拼命去搜索一个函数 $f$,让它的输出尽可能完美地拟合(Match)这串随机噪声 $\epsilon_i$”。
$\mathbb{E}_{\boldsymbol{\epsilon}}$ (对噪声取期望):这是对所有可能出现的抛硬币组合(共 $2^n$ 种序列)取平均。注意,经验复杂度 $\mathfrak{R}_S$ 是在固定了具体训练集 $S$ 的前提下计算的,所以期望只针对 $\boldsymbol{\epsilon}$ 取。
想象你给一组完全随机的数据打上标签(全是噪声)。如果你的模型空间 $\mathcal{F}$ 特别强大(比如层数极深的神经网络),它总能找到一个函数 $f$ 完美地拟合这些随机标签,让内积变得很大。
拉德马赫复杂度高 $\Rightarrow$ 模型太强了,连纯噪声都能学进去 $\Rightarrow$ 过拟合风险极高。
拉德马赫复杂度低 $\Rightarrow$ 模型比较简单,没法强行拟合噪声 $\Rightarrow$ 泛化能力可能更稳。
衡量一个模型复杂不复杂,不需要看它有多少参数,而是看它在面对随机噪声时,能不能“随波逐流”。如果它能轻易地和噪声保持一致(内积大),那它在实际应用中就很容易被数据里的干扰带偏。
复杂度性质
平移不变性 (Translation invariance)
考虑一个函数类 $\mathcal{F}$ 以及它的平移版本 $\mathcal{F}’ = {f’(\mathbf{z}) = f(\mathbf{z}) + c_0 : f \in \mathcal{F}}$,其中 $c_0 \in \mathbb{R}$ 是一个常数。那么:
$$\mathfrak{R}_S(\mathcal{F}) = \mathfrak{R}_S(\mathcal{F}’)$$
公式含义:如果你给模型库里的每一个函数都加上一个固定的常数偏移量 $c_0$(比如给神经网络最后统一加上一个固定的 Bias),这个函数空间的整体“复杂度”是完全不变的。
证明思路:只要把它代入上一页的定义式中一算就明白了: $$\frac{1}{n} \sum_{i=1}^n \epsilon_i (f(\mathbf{z}i) + c_0) = \frac{1}{n} \sum{i=1}^n \epsilon_i f(\mathbf{z}i) + \frac{c_0}{n} \sum{i=1}^n \epsilon_i$$
因为 $\epsilon_i$ 是随机抛硬币(取 $+1$ 或 $-1$ 各一半概率),所以 $\sum \epsilon_i$ 的数学期望严格等于 $0$。常数项 $c_0$ 就这样在求期望的过程中灰飞烟灭了。
物理意义:一个死板的固定常数,是不具备任何“拟合随机噪声”的能力的。它不能跟着数据的变化而变化,所以不会增加模型过拟合的风险。
缩放性质 (Scaling property)
考虑一个函数类 $\mathcal{F}$ 以及它的缩放版本 $\mathcal{F}’ = {f’(\mathbf{z}) = c \cdot f(\mathbf{z}) : f \in \mathcal{F}}$,其中 $c \in \mathbb{R}$。那么:
$$\mathfrak{R}_S(\mathcal{F}’) = |c|\mathfrak{R}_S(\mathcal{F})$$
公式含义:如果你把函数空间里所有的输出都乘以一个倍数 $c$,那么它的复杂度也会跟着放大 $|c|$ 倍。注意这里有个绝对值,因为复杂度本身定义为一个非负的期望。
证明思路:
同样代入定义式,把常数 $c$ 提出来: $$c \cdot \frac{1}{n} \sum_{i=1}^n \epsilon_i f(\mathbf{z}_i)$$
如果 $c$ 是正数,直接提出来没问题。如果 $c$ 是负数呢?因为 $\epsilon_i$ 是完全对称的随机变量,$\epsilon_i$ 和 $-\epsilon_i$ 的概率分布一模一样。所以无论你乘一个正号还是负号,它拟合噪声的期望能力只和倍数的绝对大小有关,方向无所谓。
物理意义:这很好理解,你把模型的输出范围强行放大了 $c$ 倍,它和随机噪声 $\epsilon_i$ 计算内积时的波动范围自然也就放大了 $c$ 倍。
绝对值性质 (Absolute value)
我们有:
$$\mathbb{E}{\boldsymbol{\epsilon}} \sup{f \in \mathcal{F}} \left| \sum_{i=1}^n \epsilon_i f(\mathbf{z}i) \right| \le 2 \mathbb{E}{\boldsymbol{\epsilon}} \sup_{f \in {0} \cup \mathcal{F}} \sum_{i=1}^n \epsilon_i f(\mathbf{z}_i)$$
如果我们在求上确界 $\sup$ 的内部加上了一个绝对值 $|\cdot|$,那么它的期望,不会超过原函数空间(再并上一个恒为 0 的函数)复杂度的 2 倍。
这个不等式看起来有点跳跃,其实它利用了一个基础的绝对值展开技巧。
对于任意实数 $x$,有 $|x| = \max(x, -x)$。所以左边的绝对值可以拆开:
$$\sup_{f} | \sum \epsilon_i f(\mathbf{z}_i) | = \sup_f \max \left( \sum \epsilon_i f(\mathbf{z}_i), -\sum \epsilon_i f(\mathbf{z}_i) \right)$$
这等价于我们要么取正的,要么取负的。通过三角不等式和对称性放缩,可以将其拆分为两部分的和,从而产生那个系数 $2$。同时,为了保证 $\sup$ 出来的值是非负的,我们在右边的函数空间里塞进去了一个常数函数 ${0}$,这样哪怕所有 $f$ 算出来都是负的,我们保底还能取个 0,确保了不等式符号的严格成立。
在很多理论推导的中间步骤,我们会遇到带绝对值的差值。有了这个性质,我们就可以毫不犹豫地把绝对值扔掉,代价仅仅是前面多乘一个 $2$(这在只关注收敛阶数的复杂度分析中,常数 $2$ 是完全可以接受的)。
凸包的 Rademacher 复杂度 (Rademacher complexity of convex hull)
令 $\Delta_m = {\mathbf{c} \in \mathbb{R}^m : c_j \ge 0, \sum_{j=1}^m c_j = 1}$。函数类 $\mathcal{F}$ 的凸包(记为 $\text{conv}(\mathcal{F})$)定义为:
$$\text{conv}(\mathcal{F}) = \left{ \sum_{j=1}^m c_j f_j : m \in \mathbb{N}, \mathbf{c} \in \Delta_m, f_j \in \mathcal{F} \right}$$
我们有:
$$\mathfrak{R}_S(\text{conv}(\mathcal{F})) = \mathfrak{R}_S(\mathcal{F})$$
具体推导如下:
将一个函数空间通过线性组合(凸组合)进行极大的扩充,其 Rademacher 复杂度完全不会增加。
在进入公式之前,我们先理解一下“扩充”了什么:
单纯形 $\Delta_m$:定义了一个权重向量 $\mathbf{c}$,要求所有权重非负且总和为 1。
凸包 $\text{conv}(\mathcal{F})$:它是从原始空间 $\mathcal{F}$ 中随机挑出 $m$ 个函数,按照权重 $\mathbf{c}$ 进行加权平均得到的新函数集合。$$\text{conv}(\mathcal{F}) = \left{ \sum_{j=1}^m c_j f_j : m \in \mathbb{N}, \mathbf{c} \in \Delta_m, f_j \in \mathcal{F} \right}$$ 直观理解:如果 $\mathcal{F}$ 是几个点,$\text{conv}(\mathcal{F})$ 就是包裹这些点的最小凸多边形内部的所有点。在函数空间里,这意味着即使你把空间里的函数“揉”在一起做加权平均,得到的复杂度也和原来一样。 $$\mathfrak{R}_S(\text{conv}(\mathcal{F})) = \mathfrak{R}_S(\mathcal{F})$$ 这个结论非常重要。它告诉我们,Rademacher 复杂度只取决于函数空间的“极值点”或“边界”,而与其内部的线性组合无关。
证明利用了一个核心数学观察:一个线性函数在凸集上的最大值,一定会在其顶点(端点)处取得。
推导步骤 1:展开定义
将 $f \in \text{conv}(\mathcal{F})$ 替换为加权形式 $\sum c_j f_j$: $$\mathbb{E}\epsilon \sup{f \in \text{conv}(\mathcal{F})} \sum_{i=1}^n \epsilon_i f(\mathbf{z}i) = \mathbb{E}\epsilon \sup_{\mathbf{c} \in \Delta_m, f_j \in \mathcal{F}} \sum_{i=1}^n \sum_{j=1}^m \epsilon_i c_j f_j(\mathbf{z}_i)$$
推导步骤 2:交换求和顺序
我们将权重 $c_j$ 提出来,把针对噪声的求和放在内部: $$= \mathbb{E}\epsilon \sup{\mathbf{c} \in \Delta_m, f_j \in \mathcal{F}} \sum_{j=1}^m c_j \left( \sum_{i=1}^n \epsilon_i f_j(\mathbf{z}_i) \right)$$
推导步骤 3:利用顶点最大值原理
注意括号里的项 $\alpha_j = \sum_{i=1}^n \epsilon_i f_j(\mathbf{z}_i)$ 只是一个数值。因为 $\sum c_j = 1$ 且 $c_j \ge 0$,所以 $\sum c_j \alpha_j$ 的最大值一定是让所有的权重都给到最大的那个 $\alpha_j$。
即:$\sup_{\mathbf{c} \in \Delta_m} \sum c_j \alpha_j = \max_j \alpha_j$。
推导步骤 4:回归原始复杂度
既然最大值在某个 $j$ 处取得,而这个 $f_j$ 本身就属于原始空间 $\mathcal{F}$,那么: $$= \mathbb{E}\epsilon \sup{f_j \in \mathcal{F}} \max_{j \in [m]} \sum_{i=1}^n \epsilon_i f_j(\mathbf{z}i) = \mathbb{E}\epsilon \sup_{f \in \mathcal{F}} \sum_{i=1}^n \epsilon_i f(\mathbf{z}_i)$$
超额风险界 (Excess Risk Bound)
我们在之前的对称化引理中证明了一个关键结论:
$$\mathbb{E} \left[ \sup_{\mathbf{w} \in \mathcal{W}} \frac{1}{n} \sum_{i=1}^n (\mathbb{E}_{\mathbf{z}}[f(\mathbf{w}; \mathbf{z})] - f(\mathbf{w}; \mathbf{z}_i)) \right] \le 2 \mathbb{E}_S [\mathfrak{R}_S(\mathcal{F})]$$
这里把那个难搞的“期望偏差项”变成了 2 倍的平均拉德马赫复杂度。就得到了下方的定理。
在 ERM 算法下,以至少 $1 - \delta$ 的置信度,学出来的模型 $A(S)$ 离最优模型 $\mathbf{w}^$ 的差距被锁死: $$F(A(S)) - F(\mathbf{w}^) \le \sqrt{2} n^{-\frac{1}{2}} \log^{\frac{1}{2}}(2/\delta) + 2 \mathbb{E}_S [\mathfrak{R}_S(\mathcal{F})]$$ 这个公式的局限性:
注意右边的 $\mathbb{E}_S [\mathfrak{R}_S(\mathcal{F})]$ 是一个理论期望值。它依赖于我们并不知道的数据真实分布。在实际训练模型时,我们手里只有一堆样本 $S$,算不出这个期望。
为了让公式真正能算出来,展示如何用手中的样本 $S$ 来替换掉那个“理论期望”:
稳定性证明:首先证明经验拉德马赫复杂度 $\mathfrak{R}_S(\mathcal{F})$ 本身满足有界差分条件(即改变一个样本,其变动极小)。
套用 McDiarmid:既然它很稳,那么它就会紧紧集中在其期望值附近。以 $1 - \delta/3$ 的概率:$$\mathbb{E}_S [\mathfrak{R}_S(\mathcal{F})] \le \mathfrak{R}_S(\mathcal{F}) + 2^{-1/2} n^{-\frac{1}{2}} \log^{\frac{1}{2}}(3/\delta)$$
最终合体:利用 Union Bound 把所有不确定性合在一起,得到最终以至少 $1 - \delta$ 概率成立的公式:$$F(A(S)) - F(\mathbf{w}^*) \le \frac{3 \log^{\frac{1}{2}}(3/\delta)}{\sqrt{2n}} + 2 \mathfrak{R}_S(\mathcal{F})$$ 即使我们完全不知道数据的真实分布,只要我们有足够的数据 ($n$ 大) 且我们的模型在当前数据上的复杂度受控 ($\mathfrak{R}_S$ 小),我们就能从数学上确信我们的模型是有效的。
Talagrand 收缩引理 (Talagrand’s Contraction Lemma)
$G$-Lipschitz 条件
引理的基础是函数 $\phi_i$ 必须满足 Lipschitz 连续性。
定义:设 $\phi_i: \mathbb{R} \mapsto \mathbb{R}$ 是 $G$-Lipschitz 的,即: $$|\phi_i(a) - \phi_i(b)| \le G|a - b|$$
直观理解:函数的“斜率”或变化率被常数 $G$ 给封顶了。在机器学习中,绝大多数常用的函数都满足这个条件,比如 ReLU ($G=1$)、Sigmoid ($G=1/4$) 以及各种常见的损失函数。
引理给出了复合函数空间复杂度的上界:
$$\mathbb{E}\epsilon \sup{f \in \mathcal{F}} \sum_{i=1}^n \epsilon_i \phi_i(f(\mathbf{z}i)) \le G \mathbb{E}\epsilon \sup_{f \in \mathcal{F}} \sum_{i=1}^n \epsilon_i f(\mathbf{z}_i)$$
深度解读:
“收缩”在哪里?:左边是经过非线性变换 $\phi_i$ 后的复杂度,右边是原始复杂度乘以 Lipschitz 常数 $G$。
物理意义:如果一个非线性变换是平滑的(变化不剧烈),那么它不会显著增加模型拟合噪声的能力。它对复杂度的贡献最多只是线性地放大 $G$ 倍。
它在机器学习中最常用的形式:剥离非线性算子。
复合函数类:定义 $\phi \circ \mathcal{F} = {\mathbf{z} \mapsto \phi(f(\mathbf{z})) : f \in \mathcal{F}}$。
结论公式: $$\mathfrak{R}_S(\phi \circ \mathcal{F}) \le G \mathfrak{R}_S(\mathcal{F})$$ 为什么这个结论是“救命”的?
在推导神经网络的泛化界限时,每一层都有一个非线性激活函数。有了这个引理,我们可以像剥洋葱一样,一层一层地把激活函数剥掉,最终将复杂的深层网络的复杂度简化为对线性层权重的分析。
只要非线性变换是“温和”的(Lipschitz 连续),它就不会创造出额外的过拟合风险。 这解释了为什么我们可以堆叠很多层非线性激活函数,而模型的泛化误差依然受控。
例子
回顾一下公式: $$F(A(S)) - F(\mathbf{w}^*) \le \frac{3 \log^{\frac{1}{2}}(3/\delta)}{\sqrt{2n}} + 2\mathfrak{R}_S(\mathcal{F})$$
左边:超额风险(Excess Risk),即学出来的模型与理论最优模型的差距。
右边最后两项:采样随机性带来的误差,以及损失函数类 $\mathcal{F}$ 的经验拉德马赫复杂度。
为了进一步简化 $\mathfrak{R}_S(\mathcal{F})$,我们引入了 $G$-Lipschitz 假设。
如果损失函数 $\ell$ 满足:
$$|\ell(a, y) - \ell(a’, y)| \le G|a - a’|$$
这意味着损失函数的变化是平滑受控的,不会因为预测值的微小改变而产生剧烈波动。
定义空间:$\mathcal{H}$ 是我们的假设空间(模型预测值的集合),而 $\mathcal{F}$ 是损失函数作用后的空间。
应用 Talagrand 引理: $$\mathfrak{R}S(\mathcal{F}) = \mathfrak{R}S(\mathbf{z} \mapsto \ell(h{\mathbf{w}}(\mathbf{x}), y) : \mathbf{w} \in \mathcal{W})$$$$\dots = \frac{1}{n} \mathbb{E}\epsilon \sup_{\mathbf{w} \in \mathcal{W}} \left[ \sum_{i=1}^n \epsilon_i \ell(h_{\mathbf{w}}(\mathbf{x}_i), y_i) \right]$$
剥离损失函数:由于 $\ell$ 是 $G$-Lipschitz 的,根据收缩引理,我们可以直接把 $\ell$ 拿掉,前面乘上斜率上限 $G$: $$\le \frac{G}{n} \mathbb{E}\epsilon \sup{\mathbf{w} \in \mathcal{W}} \left[ \sum_{i=1}^n \epsilon_i h_{\mathbf{w}}(\mathbf{x}_i) \right] = G \mathfrak{R}_S(\mathcal{H})$$

通过 Lipschitz 性质,我们将损失函数类的复杂度缩减为了假设空间的复杂度!
最终,以至少 $1 - \delta$ 的概率,超额风险满足:
$$F(A(S)) - F(\mathbf{w}^*) \le \frac{3 \log^{\frac{1}{2}}(3/\delta)}{\sqrt{2n}} + 2G \mathfrak{R}_S(\mathcal{H})$$ 这个公式解释了机器学习中一个非常深刻的直觉:
模型复杂度 ($\mathfrak{R}_S(\mathcal{H})$):如果你用一个极其复杂的模型(比如参数超多的深度网络),那么泛化误差的上界会变大。
损失函数的敏感度 ($G$):如果你的损失函数对误差非常敏感($G$ 很大),那么泛化风险也会相应增加。
样本量 ($n$):数据越多,随机误差项消失得越快。
只要你的损失函数是 Lipschitz 连续的(比如常见的 Cross-Entropy, Hinge Loss, $L_2$ Loss 等),你就不需要操心损失函数本身有多复杂,只需要死死盯着你的模型复杂度 $\mathfrak{R}_S(\mathcal{H})$ 就可以了。
马萨特引理
Massart 引理就是用来给最底层的有限个元素直接“宣判”复杂度上限的。只要涉及到有限个向量或者有限个顶点的假设空间,最后一步全都是靠 Massart 引理来收尾的。
假设 $A$ 是 $\mathbb{R}^n$ 空间中的一个有限向量集合,并且对于集合 $A$ 中的任意向量 $\mathbf{a}$,都满足 L2 范数有界:$|\mathbf{a}|_2 \le r$。
那么:
$$\mathbb{E}\Big[\sup_{\mathbf{a} \in A} \frac{1}{n} \sum_{i=1}^n \epsilon_i a_i\Big] \le \frac{r(2\log|A|)^{\frac{1}{2}}}{n}$$
前提条件 $\mathbf{a} \in \mathbb{R}^n$ 与 $|\mathbf{a}|_2 \le r$:
这里的 $\mathbf{a}$ 是一个 $n$ 维向量,你可以把它想象成“某个模型在 $n$ 个训练样本上的输出值序列”,即 $(a_1, a_2, \dots, a_n)$。$|\mathbf{a}|_2 \le r$ 意味着这个输出向量的欧氏距离(L2范数)被一个半径 $r$ 封顶了。
公式左边:
$\mathbb{E}\big[\sup \frac{1}{n} \sum \epsilon_i a_i\big]$ 这个形式你已经非常熟悉了,它完全就是 Rademacher 复杂度的定义式,表示集合 $A$ 拟合纯随机噪声 $\epsilon_i$ 的能力。
公式右边(极其关键的 $\log$):
上界是 $\frac{r\sqrt{2\log|A|}}{n}$。这个界限里最牛的地方在于 $\log|A|$。$|A|$ 代表集合里向量的个数。因为带了对数 $\log$,这意味着即使你的集合非常庞大(比如有 $2^d$ 个元素),它对复杂度的贡献也会被 $\log$ 大幅压缩(变成 $d \log 2$)。
- 实战联想: 把 $L_1$ 范数的球拆解成了 $2d$ 个顶点组成的集合,然后直接套用 Massart 引理,最后复杂度里就完美出现了 $\sqrt{\log(2d)}$。
Finite Class (有限函数类)
有限函数类 $\mathcal{F}$:假设你的模型空间里只有有限个候选函数(比如 $| \mathcal{F} | = 100$ 个不同的分类器)。
输出有界性:规定对于任何输入 $\mathbf{z}$,函数的输出幅度 $|f(\mathbf{z})| \le 1$。
- 这意味着函数向量的每一个分量都在 $[-1, 1]$ 之间。
如何将这个问题转化为向量集 $A$:
向量化:将每个函数在 $n$ 个样本上的输出写成一个 $n$ 维向量: $$A = { (f(\mathbf{z}_1), \dots, f(\mathbf{z}_n)) : f \in \mathcal{F} }$$
确定半径 $r$:
由于每个分量 $|f(\mathbf{z}_i)| \le 1$,那么向量的 $L_2$ 范数平方 $\sum f(\mathbf{z}_i)^2 \le \sum 1 = n$。
因此,向量的模长(半径)满足: $$|\mathbf{a}| \le \sqrt{n} \quad (\text{即 } r = \sqrt{n})$$
我们将 $r = \sqrt{n}$ 代入 Massart 引理的通用公式 $\frac{r(2 \log |A|)^{\frac{1}{2}}}{n}$ 中:
$$\mathfrak{R}_S(\mathcal{F}) \le \frac{\sqrt{n} \cdot (2 \log |\mathcal{F}|)^{\frac{1}{2}}}{n}$$
简化后得到本页的核心公式:
$$\mathfrak{R}_S(\mathcal{F}) \le \left( \frac{2 \log |\mathcal{F}|}{n} \right)^{\frac{1}{2}}$$
这个结论在机器学习理论中极其重要,因为它解释了奥卡姆剃刀原理的数学本质:
对数据量 $n$ 的依赖:复杂度随 $1/\sqrt{n}$ 消失。这意味着只要数据量足够大,任何有限的模型空间最终都会“收敛”,不会过拟合。
对空间大小 $|\mathcal{F}|$ 的依赖:
即使你的模型空间非常大(比如有 $10^{10}$ 个模型),由于 $\log$ 的存在,其复杂度也仅仅增加了一点点。
这说明增加模型的“备选项”数量,并不会剧烈地破坏泛化能力,真正危险的是让模型在单个维度上拥有无限的取值能力(即无限的 VC 维或无限的范数)。
线性函数类的 Rademacher 复杂度
定义我们的模型空间:
$$\mathcal{H} = {\mathbf{x} \mapsto \mathbf{w}^\top \mathbf{x} : |\mathbf{w}|_2 \le 1}$$
线性模型:预测值为 $\mathbf{w}^\top \mathbf{x}$。
$L_2$ 范数限制:要求权重向量的长度 $|\mathbf{w}|_2 \le 1$。
- 工程直觉:这其实就是我们在训练 SVM 或逻辑回归时加的 $L_2$ 正则化惩罚项。如果不限制 $|\mathbf{w}|_2$,模型为了强行拟合噪声,参数会膨胀到无限大,复杂度也会爆炸。
首先代入 Rademacher 复杂度的定义:
$$\mathfrak{R}S(\mathcal{H}) = \frac{1}{n} \mathbb{E}\epsilon \sup_{h \in \mathcal{H}} \sum_{i=1}^n \epsilon_i h(\mathbf{x}i) = \frac{1}{n} \mathbb{E}\epsilon \sup_{\mathbf{w}: |\mathbf{w}|2 \le 1} \mathbf{w}^\top \left( \sum{i=1}^n \epsilon_i \mathbf{x}_i \right)$$
这里利用求和的线性性质,把模型权重 $\mathbf{w}$ 提了出来。
接下来,根据柯西-施瓦茨不等式(两向量内积 $\le$ 模长之积),我们有:
$$\le \frac{1}{n} \mathbb{E}\epsilon \sup{\mathbf{w}: |\mathbf{w}|_2 \le 1} |\mathbf{w}|2 \left| \sum{i=1}^n \epsilon_i \mathbf{x}_i \right|_2$$
因为我们限定了 $|\mathbf{w}|_2 \le 1$,所以可以直接把 $|\mathbf{w}|2$ 替换为 1,从而彻底消灭了那个麻烦的 $\sup{\mathbf{w}}$:
$$\le \frac{1}{n} \mathbb{E}\epsilon \left( \left| \sum{i=1}^n \epsilon_i \mathbf{x}_i \right|_2^2 \right)^{\frac{1}{2}}$$
由于平方根函数 $\sqrt{x}$ 是凹函数(Concave),根据 Jensen 不等式 $\mathbb{E}[\sqrt{X}] \le \sqrt{\mathbb{E}[X]}$,我们可以把外面求期望的操作 $\mathbb{E}_\epsilon$ 塞到根号里面去:
$$\mathfrak{R}S(\mathcal{H}) \le \frac{1}{n} \left( \mathbb{E}\epsilon \left| \sum_{i=1}^n \epsilon_i \mathbf{x}_i \right|_2^2 \right)^{\frac{1}{2}}$$
展开平方,利用噪声独立性消灭交叉项
把平方和展开变成两重求和:
$$= \frac{1}{n} \left( \mathbb{E}\epsilon \sum{i,j=1}^n \epsilon_i \epsilon_j \mathbf{x}_i^\top \mathbf{x}_j \right)^{\frac{1}{2}}$$
把这堆求和拆分成两部分:$i = j$ 的自身项,和 $i \neq j$ 的交叉项。
$$= \frac{1}{n} \left( \mathbb{E}\epsilon \sum{i=1}^n \epsilon_i^2 \mathbf{x}i^\top \mathbf{x}i + \sum{i \neq j} \mathbb{E}\epsilon [\epsilon_i \epsilon_j] \mathbf{x}_i^\top \mathbf{x}_j \right)^{\frac{1}{2}}$$
自身项:因为 $\epsilon_i \in {-1, 1}$,所以 $\epsilon_i^2$ 永远等于 1。
交叉项:当 $i \neq j$ 时,由于 $\epsilon_i$ 和 $\epsilon_j$ 是互相独立且均值为 0 的抛硬币结果,所以它们的联合期望 $\mathbb{E}[\epsilon_i \epsilon_j] = \mathbb{E}[\epsilon_i]\mathbb{E}[\epsilon_j] = 0 \times 0 = 0$。
所有的交叉项全部灰飞烟灭!只剩下了自身项的 $L_2$ 范数平方:
$$= \frac{1}{n} \left( \sum_{i=1}^n |\mathbf{x}_i|_2^2 \right)^{\frac{1}{2}}$$ 结合我们在上一页得出的 Lipschitz 损失函数泛化公式,直接把算出来的 $\mathfrak{R}_S(\mathcal{H})$ 替换进去,我们就得到了本页底部的最终大招:
$$\implies F(A(S)) - F(\mathbf{w}^*) \le \frac{3 \log^{\frac{1}{2}}(3/\delta)}{\sqrt{2n}} + \frac{2G}{n} \left( \sum_{i=1}^n |\mathbf{x}_i|2^2 \right)^{\frac{1}{2}}$$ 最右边的那一项:$\left( \sum{i=1}^n |\mathbf{x}_i|_2^2 \right)^{\frac{1}{2}}$。
它说明了:线性分类器的泛化能力,完全取决于训练数据的范数大小(也就是数据点离原点有多远),而与数据的维度 $d$ 毫无关系!
在没有看到这个证明之前,我们可能会凭直觉认为,特征维度越高(比如一万维的输入),模型越容易过拟合。但这套理论告诉你:只要你限制了权重 $|\mathbf{w}|_2 \le 1$,即使特征维度趋于无限大,只要数据的模长受控,泛化误差就依然受控。这正是核方法(Kernel Methods)和 SVM 能够在无限维特征空间中依然有效的不败基石。
浅层 ReLU 神经网络的 Rademacher 复杂度
定义了我们的浅层(单隐层)ReLU 神经网络:
$$\mathcal{H} = \left{ \sum_{j=1}^m a_j \sigma(\mathbf{w}j^\top \mathbf{x}) : \sum{j=1}^m |a_j| |\mathbf{w}_j|_2 \le R \right}$$
结构:$m$ 是隐藏层神经元的个数;$\mathbf{w}_j$ 是输入层到第 $j$ 个神经元的内层权重;$a_j$ 是隐层到输出层的外层权重。
激活函数:$\sigma(t) = \max{t, 0}$ 就是大家非常熟悉的 ReLU。
全局约束(极度关键):$\sum_{j=1}^m |a_j| |\mathbf{w}_j|_2 \le R$。这是一种特殊形式的权重衰减(Weight Decay),被称为 Path Norm(路径范数)。它限制了整个网络所有路径上权重乘积的绝对值之和。
ReLU 有一个非常棒的性质:对于任何非负数 $a \ge 0$,都有 $\sigma(ta) = a\sigma(t)$。
- 直观理解:无论你在 ReLU 外面乘一个正数,还是在里面乘一个正数,结果是一样的。这是接下来“提取公因式”的核心武器。
第一步:代入模型定义
直接把网络输出 $h(\mathbf{x}_i)$ 替换成求和公式:
$$n\mathfrak{R}S(\mathcal{H}) = \mathbb{E}\epsilon \sup_{h \in \mathcal{H}} \sum_{i=1}^n \epsilon_i h(\mathbf{x}i) = \mathbb{E}\epsilon \sup_{h \in \mathcal{H}} \sum_{i=1}^n \epsilon_i \sum_{j=1}^m a_j \sigma(\mathbf{w}_j^\top \mathbf{x}_i)$$
第二步:利用正齐次性进行“归一化”
这是一个非常秀的操作。我们在 ReLU 内部除以 $|\mathbf{w}_j|_2$,然后在外部乘上 $|\mathbf{w}_j|_2$。因为范数必然是非负的,所以完美符合 ReLU 的正齐次性:
$$= \mathbb{E}\epsilon \sup{h \in \mathcal{H}} \sum_{i=1}^n \sum_{j=1}^m \epsilon_i a_j |\mathbf{w}_j|_2 \sigma(\mathbf{w}_j^\top \mathbf{x}_i / |\mathbf{w}_j|_2)$$
- 目的:把 $\mathbf{w}_j$ 变成了单位向量(长度为 1),把它的“大小”提取到了外面。
第三步:交换求和顺序与符号拆解
把针对神经元 $j$ 的求和提到外面,针对样本 $i$ 的求和放到里面。同时,把外层权重 $a_j$ 拆成绝对值和符号函数的乘积:$a_j = |a_j|\text{sgn}(a_j)$。
$$= \mathbb{E}\epsilon \sup{h \in \mathcal{H}} \sum_{j=1}^m |a_j| |\mathbf{w}_j|2 \text{sgn}(a_j) \sum{i=1}^n \epsilon_i \sigma(\mathbf{w}_j^\top \mathbf{x}_i / |\mathbf{w}_j|_2)$$
第四步:不等式放缩 (The Crucial Inequality)
这里用了一个类似加权求和的不等式技巧:如果有 $\sum \text{非负权重} \times \text{某项数值}$,它一定小于等于 $(\sum \text{非负权重}) \times (\text{这些数值中的最大绝对值})$。
在这里,“非负权重”就是 $|a_j| |\mathbf{w}_j|_2$,我们把后面的求和项取所有 $m$ 个神经元中的最大绝对值:
$$\le \mathbb{E}\epsilon \sup{h \in \mathcal{H}} \sum_{j=1}^m |a_j| |\mathbf{w}j|2 \max{j \in [m]} \left| \text{sgn}(a_j) \sum{i=1}^n \epsilon_i \sigma(\mathbf{w}_j^\top \mathbf{x}_i / |\mathbf{w}_j|_2) \right|$$
第五步:代入约束,彻底降维
前面的求和部分 $\sum_{j=1}^m |a_j| |\mathbf{w}_j|_2$,根据我们一开始的模型约束,它最大就是 $R$。
后面的 $\max_{j \in [m]}$ 是在具体的 $m$ 个神经元里挑最大的。我们干脆把它放缩成:在所有可能的单位权重向量 $\mathbf{w}$ 中取上确界 $\sup_{\mathbf{w}}$(而且 $\text{sgn}(a_j)$ 只是一个正负号,可以被绝对值吸收掉)。
$$\le R \mathbb{E}\epsilon \sup{\mathbf{w}} \left| \sum_{i=1}^n \epsilon_i \sigma(\mathbf{w}^\top \mathbf{x}_i / |\mathbf{w}|_2) \right|$$
最后的公式,里面没有表示网络宽度的 $m$ 了。 这意味着:浅层神经网络的 Rademacher 复杂度,并不直接依赖于隐藏层神经元的数量 $m$(即使 $m$ 趋于无穷大),而是受到权重路径范数 $R$ 的控制。
这就是为什么我们在训练极宽的神经网络时,只要加上合理的权重正则化,模型依然能保持极好的泛化能力。
现在我们得到的是 $$n\mathfrak{R}S(\mathcal{H}) \le R \mathbb{E}\epsilon \sup_{\mathbf{w}} \left| \sum_{i=1}^n \epsilon_i \sigma(\mathbf{w}^\top \mathbf{x}_i / |\mathbf{w}|_2) \right|$$ 令 $\tilde{\mathbf{w}} = \mathbf{w} / |\mathbf{w}|2$。显然,这个新向量的 $L_2$ 范数为 1(我们可以放宽到 $|\tilde{\mathbf{w}}|2 \le 1$ 形成一个凸集,不影响上确界)。 $$n\mathfrak{R}S(\mathcal{H}) \le R \mathbb{E}\epsilon \sup{\tilde{\mathbf{w}}: |\tilde{\mathbf{w}}|2 \le 1} \left| \sum{i=1}^n \epsilon_i \sigma(\tilde{\mathbf{w}}^\top \mathbf{x}i) \right|$$ 带绝对值的 Rademacher 复杂度处理方法:直接去掉绝对值,并在前面乘上一个 2: $$\le 2R \mathbb{E}\epsilon \sup{\tilde{\mathbf{w}}: |\tilde{\mathbf{w}}|2 \le 1} \sum{i=1}^n \epsilon_i \sigma(\tilde{\mathbf{w}}^\top \mathbf{x}_i)$$ 这是最关键的一步!因为 $\sigma$ 是 ReLU 激活函数,而 ReLU 是 1-Lipschitz 连续的(它的斜率最大就是 1,即 $G=1$)。
根据 Talagrand 引理,我们可以直接把 ReLU 函数 $\sigma$ 扔掉,且不需要乘额外的系数: $$\le 2R \mathbb{E}\epsilon \sup{\tilde{\mathbf{w}}: |\tilde{\mathbf{w}}|2 \le 1} \sum{i=1}^n \epsilon_i \tilde{\mathbf{w}}^\top \mathbf{x}_i$$ 剩下的这部分,和我们之前推导“线性函数类” 一模一样。
提取 $\tilde{\mathbf{w}}^\top$,利用 $|\tilde{\mathbf{w}}|_2 \le 1$ 将其消掉,然后利用 $\epsilon_i$ 的独立性消灭交叉项:
$$\le 2R \mathbb{E}\epsilon \sup{\tilde{\mathbf{w}}: |\tilde{\mathbf{w}}|2 \le 1} \tilde{\mathbf{w}}^\top \left( \sum{i=1}^n \epsilon_i \mathbf{x}i \right) \le 2R \mathbb{E}\epsilon \left| \sum_{i=1}^n \epsilon_i \mathbf{x}_i \right|2 \le 2R \left( \sum{i=1}^n |\mathbf{x}_i|_2^2 \right)^{\frac{1}{2}}$$
两边同时除以 $n$,我们就得到了浅层 ReLU 神经网络在路径范数 $R$ 约束下的经验 Rademacher 复杂度:
$$\mathfrak{R}S(\mathcal{H}) \le \frac{2R}{n} \left( \sum{i=1}^n |\mathbf{x}_i|_2^2 \right)^{\frac{1}{2}}$$
这句话是这节课的核心价值所在。在传统的统计学习理论(比如 VC 维)中,模型的复杂度通常与参数的数量成正比。如果一个浅层网络有 $m$ 个隐藏神经元,参数量就是 $m \times d$。当 $m$ 非常大(甚至趋于无限)时,传统的理论会认为这个模型一定会严重过拟合。
但实际上它只取决于两个因素:
数据的规模:样本的范数和 $\sum |\mathbf{x}_i|_2^2$。
权重的正则化:路径范数 $R$。
这为现代深度学习(尤其是过参数化网络,Over-parameterized Networks)提供了强大的理论支撑:只要我们在训练时有效地控制住了权重的整体规模(比如使用 Weight Decay / $L_2$ 正则化),哪怕你把神经网络加宽到一万、一百万个神经元,它依然具有严格的泛化误差上限,不会变成脱缰的野马。
VC维
假设空间的上界
Massart 引理的作用:它为有限函数类提供了一个 Rademacher 复杂度的上界估计。
面临的问题:在实际应用中,假设空间 $\mathcal{H}$ 通常非常庞大,甚至包含无限多个假设。
评估复杂度的关键在于函数空间在训练数据集 $S$ 上的投影 (Projection):
在二元分类中,将一个假设 $h \in \mathcal{H}$ 投影到规模为 $n$ 的数据集 $S$ 上,会得到一个 $n$ 维向量。
该向量的每个分量要么是 $1$,要么是 $-1$。
投影集合的基数:定义 $\mathcal{H}_S$ 为所有可能投影结果的集合,即:
$$\mathcal{H}_S := {(h(\mathbf{x}_1), \dots, h(\mathbf{x}_n)) : h \in \mathcal{H}}$$
由于每个位置只有两种可能,该集合的基数 $|\mathcal{H}_S|$ 最大为 $2^n$。
如果该投影集合的基数达到了最大值 $2^n$(即假设空间可以打散这 $n$ 个点),根据 Massart 引理推导出的 Rademacher 复杂度 $\mathfrak{R}_S(\mathcal{H})$ 上界如下:
$$\mathfrak{R}_S(\mathcal{H}) \leq \left( \frac{2 \log |\mathcal{H}_S|}{n} \right)^{\frac{1}{2}} = \left( \frac{2n}{n} \right)^{\frac{1}{2}} = \sqrt{2}$$
- 结论:这个界限被称为 “Vacuous bound”(空洞的界限)。因为 Rademacher 复杂度本身通常在 $[0, 1]$ 之间,一个大于 $1$ 的常数上界(如 $\sqrt{2} \approx 1.414$)在数学上虽然正确,但在统计学习理论中没有实际指导意义,无法证明模型的泛化能力。
这里的关键是,虽然我们寻找模型的整个假设空间可能是无限大(比如无数条线),但如果我们把目光局限在有限的 $n$ 个训练样本上,无数个不同的假设实际上会“坍缩”成同一种分类结果。这种在有限样本上的具体分类结果就是 Dichotomy。
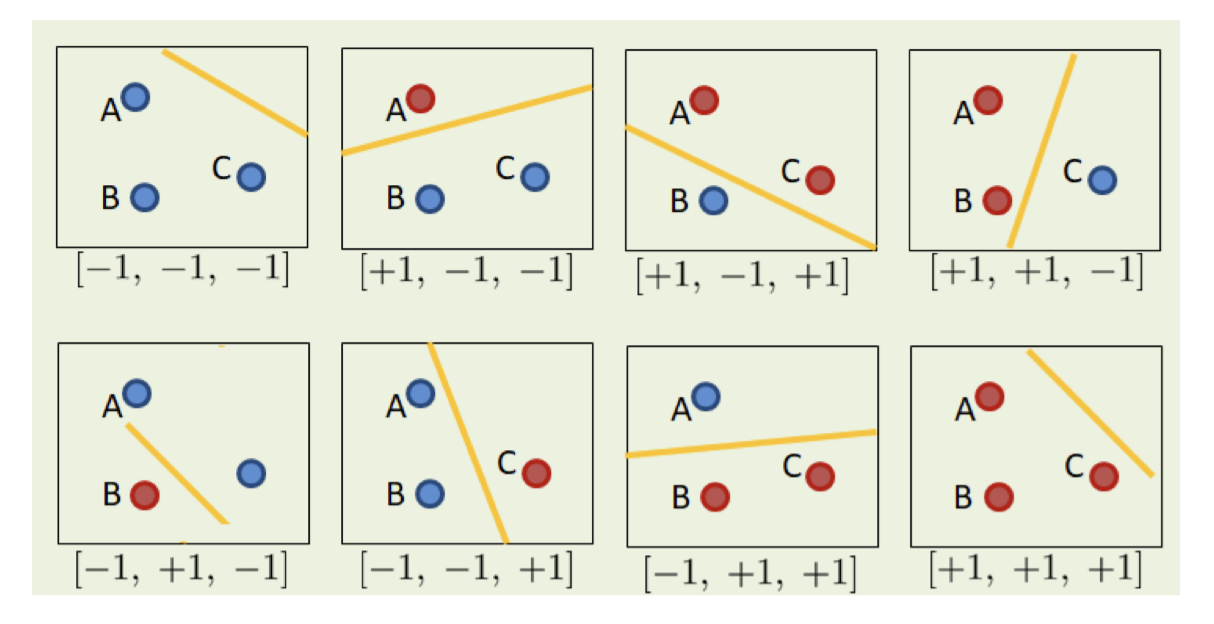
需要注意的是,这种假设空间(线性分类器)表达能力的局限性,如下图:
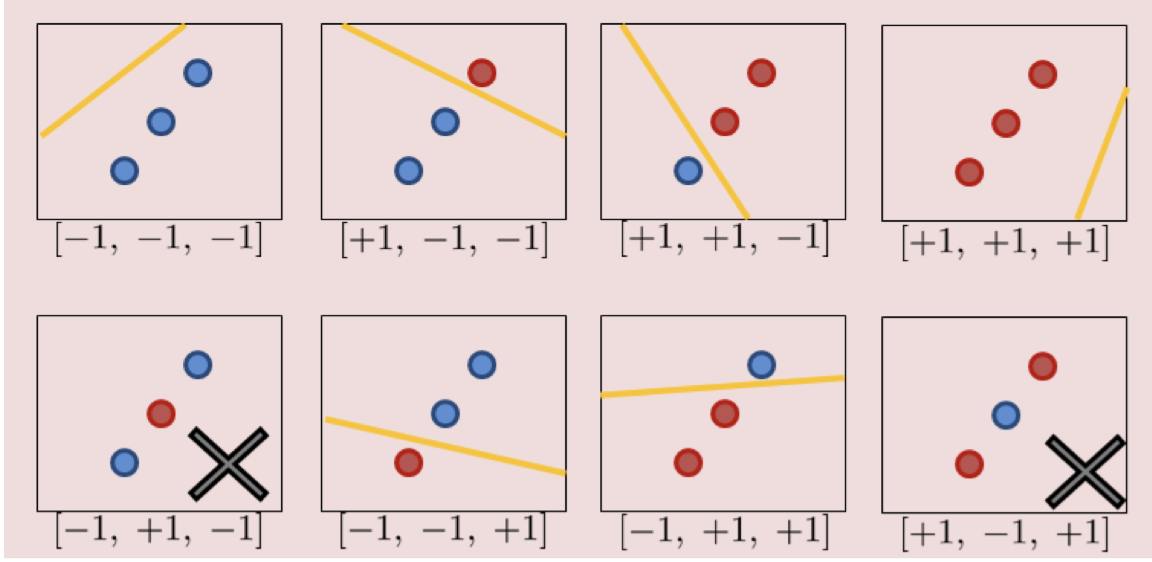
对于 3 个点,理论上每个点有 $+1$(红色)或 $-1$(蓝色)两种可能,总共有 $2^3 = 8$ 种分类组合。我们来看看一条直线(线性分类器)能否实现这 8 种分类:
成功的 6 种情况:图中没有打叉的 6 张小图。通过平移黄色的分割线,我们可以轻松实现诸如全部是一类
[-1, -1, -1]、[+1, +1, +1],或者把其中一端的一个或两个点分出去(例如[+1, -1, -1]、[+1, +1, -1]等)。失败的 2 种情况(打叉 ❌ 的图):
[-1, +1, -1]:两端是蓝点,中间是红点。[+1, -1, +1]:两端是红点,中间是蓝点。
失败原因:在二维平面上,你无法画出一条笔直的线,把夹在中间的那个点单独切分到一侧,而让两端的点在另一侧。这本质上类似于一维空间中的 XOR(异或)问题,线性分类器无法解决。
虽然对于线性分类器来说,我们经常听说“它可以打散 3 个点”(意味着 $|\mathcal{H}_S| = 2^3 = 8$),但这取决于数据点的空间分布。如果这 3 个点处于特定的“坏”位置(比如共线),那么线性分类器在这个数据集上产生的二分法集合大小就会受到限制,即 $|\mathcal{H}_S| = 6 < 8$。它无法实现所有可能的对分。
增长函数
增长函数的严谨数学定义:
$$m_{\mathcal{H}}(n) = \max_{S: |S|=n} |\mathcal{H}_S|$$
$m_{\mathcal{H}}(n)$:表示假设空间 $\mathcal{H}$ 在样本量为 $n$ 时的增长函数。
$|S|=n$:表示我们考虑的数据集 $S$ 的大小(样本数量)固定为 $n$。
$|\mathcal{H}_S|$:这是上一页学过的,假设空间 $\mathcal{H}$ 在特定数据集 $S$ 上能产生的二分法集合的大小(即能产生多少种不同的分类结果)。
$\max_{S: \dots}$:这是公式的灵魂所在。它意味着我们要遍历所有可能包含 $n$ 个点的数据集 $S$(即考虑点在空间中的所有可能排布方式),然后取其中能产生最多二分法数量的那个最大值。
对于二维线性分类器,当 $n=3$ 时:
如果 $S$ 是共线的三个点,我们在上一页看到 $|\mathcal{H}_S| = 6$。
如果 $S$ 是不共线的三个点(比如呈三角形),$|\mathcal{H}_S| = 8$。
根据增长函数的定义,我们要取最大值,所以二维线性分类器的 $m_{\mathcal{H}}(3) = \max(6, 8) = 8$
直观含义 (Intuitively):
增长函数是指假设空间 $\mathcal{H}$ 投影到任意大小为 $n$ 的样本集上时,所能产生的最大基数(即最多的分类组合数)。它消除了具体数据怎么摆放的影响,只看模型在 $n$ 个点下的“极限能力”。
物理意义 (Expressiveness):
$m_{\mathcal{H}}(n)$ 代表了假设空间 $\mathcal{H}$ 的表达能力 (expressiveness)。增长函数的值越大(最高可达 $2^n$),说明这个模型越复杂,能够拟合越多样的数据模式。
依赖关系 (Dependencies):
它只依赖于假设空间本身 ($\mathcal{H}$) 和样本的数量 ($n$)。
它不依赖于具体的学习算法(比如你是用梯度下降还是什么其他方法来找这个模型)。
它不依赖于具体的训练数据集 $S$(因为公式里已经用 $\max$ 把 $S$ 给消掉了,我们考虑的是最坏/最极端情况下的数据集)。
机器学习理论中,当一个模型在 $n$ 个点上能产生 $2^n$ 种二分法时,我们称这个模型能够 打散 (Shatter) 这 $n$ 个点。这也暗示了二维线性分类器的表达能力足以完全拟合 3 个点的任何分类情况。但是$m_{\mathcal{H}}(4) = 14$,因为 $m_{\mathcal{H}}(4) = 14 < 2^4 = 16$,所以二维线性分类器无法“打散 (shatter)” 4 个点。
这说明当 $n=4$ 时,二维线性模型的表达能力遇到了天花板,它不再能像 $n=3$ 时那样拟合所有可能的标签组合。
接下来我们来看二维凸集 (Convex Sets in 2D)。
假设空间 $\mathcal{H}$ 的集合定义:
$$ \mathcal{H} = {h: \mathbb{R}^2 \mapsto {+1, -1} \text{ s.t. } {\mathbf{x}: h(\mathbf{x}) = 1} \text{ is convex}} $$
公式深度拆解:
$h: \mathbb{R}^2 \mapsto {+1, -1}$:这表示假设空间里的每一个模型 $h$ 都是一个二元分类器,它将二维平面 ($\mathbb{R}^2$) 上的点映射为正类 ($+1$) 或负类 ($-1$)。
$\text{s.t.}$:是 “subject to” 的缩写,意为“满足以下条件”。
${\mathbf{x}: h(\mathbf{x}) = 1} \text{ is convex}$:这是最核心的限制条件。它要求所有被预测为正类 ($+1$) 的数据点 $\mathbf{x}$ 所构成的集合,必须是一个凸集 (convex set)。把分类边界升级成了一个可以任意变形、但必须保持“凸”的闭合图形。你可以预见到,这种分类器的表达能力(增长函数 $m_{\mathcal{H}}(n)$)会比直线强大得多,它能实现极其复杂的分类组合。
二维凸集这个假设空间的增长函数 $m_{\mathcal{H}}(n)$ 是多少?答案是 $2^n$(即它可以打散任意数量的样本点)。
- 寻找最优的样本排布方式
“Put all $n$ points on a circle.” (将所有 $n$ 个点放在一个圆上)
为了求增长函数(即最大化二分法数量),我们需要找到一种“最好”的点排布方式。这里给出的绝妙策略是:把所有数据点都放在圆周上。图右侧的灰色圆圈和上面的红蓝点正是这个设定的可视化。
- 构造分类器 (核心逻辑与公式)
接下来,对于圆上的这 $n$ 个点,无论你怎么给它们分配正负标签(也就是任意一种 Dichotomy),我们都能用一个“凸集”把所有的正例完美圈起来,同时把所有的负例排除在外。
提取正例:对于任意一种正负标签分配方案,假设其中的正例(Positive examples)为 $\mathbf{x}{i_1}, \dots, \mathbf{x}{i_m}$。(图中的蓝色带
+号的点)。构造凸包 (Convex Hull):用这些正例作为顶点,构造一个凸包(图中蓝色的多边形区域)。
PPT 给出了这个凸包 $\mathcal{X}_+$ 的严谨数学定义:
$$ \mathcal{X}+ = \left{ \sum{j=1}^m \alpha_j \mathbf{x}{i_j} : \alpha_j \in [0, 1], \sum{j=1}^m \alpha_j = 1 \right}. $$
- 公式解释:这是一个标准的凸组合 (Convex Combination) 定义。它表示由所有正例点 $\mathbf{x}_{i_j}$ 按照一定权重 $\alpha_j$ 线性组合而成的所有点的集合。由于权重非负且和为 1,这个集合在几何上就完美对应了以这些正例为顶点的凸多边形(包括边界和内部)。
定义假设函数 $h(\mathbf{x})$:
有了凸包之后,我们就可以定义我们具体的分类模型 $h(\mathbf{x})$ 了:
$$ h(\mathbf{x}) = \begin{cases} 1, & \text{if } \mathbf{x} \in \mathcal{X}_+ \ -1, & \text{otherwise}. \end{cases} $$
- 公式解释:如果一个点落在这个凸包内部或边界上,就预测为正类 ($+1$);如果落在外面,就预测为负类 ($-1$)。
- 为什么这个构造是完美的?
“Then $h(\mathbf{x}_i) = -1$ if and only if $\mathbf{x}_i$ is a negative example”
这句话点出了圆周排布的精妙之处:因为所有的点都在圆周上,所以任意几个点连成的多边形(凸包),其内部绝对不可能包含圆周上的其他点。
因此,所有的正例都在边界上(被正确分类为 $+1$),而所有的负例都在圆周上且在这个凸包的外部(被正确分类为 $-1$)。不会有任何一个负例被“误伤”圈进凸包里。
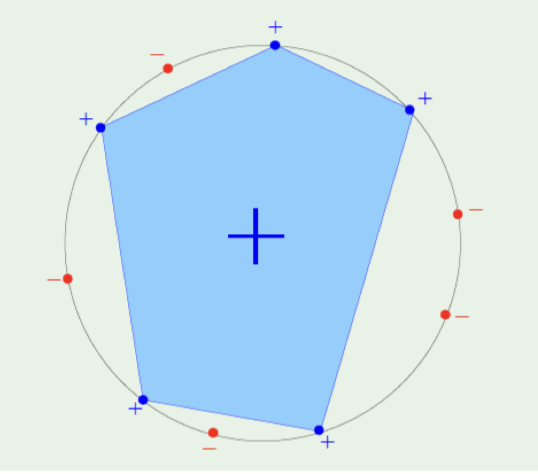
- 最终结论 (增长函数公式)
因为对于任意的 $n$ 个点,只要我们把它们放在圆上,无论这 $2^n$ 种标签组合是哪一种,我们都能照猫画虎画出一个凸多边形完美分类。
“We can get $2^n$ different dichotomies, and this is the best possible one”(我们可以得到 $2^n$ 种不同的二分法,这是可能达到的最好结果)。
因此,PPT 给出了最终的增长函数公式:
$$ m_{\mathcal{H}}(n) = 2^n, \quad \forall n \in \mathbb{N}. $$
打散 (Shatter)
定义:如果一个假设空间 $\mathcal{H}$ 能够产生所有可能的 $2^n$ 种对分(dichotomies),那么我们就说 $\mathcal{H}$ 打散 (shatters) 了这 $n$ 个样本点 $\mathbf{x}_1, \dots, \mathbf{x}_n$。
通俗理解:这意味着无论这 $n$ 个点在空间中被赋予怎样的正负标签(哪怕是最刁钻的组合),你的模型 $\mathcal{H}$ 都能找出一个完美的边界把它们完全正确地分开。这代表模型在面对这 $n$ 个点时,表达能力达到了极限。
VC维 (VC Dimension)
定义:假设空间 $\mathcal{H}$ 的 VC 维,记作 $d_{\text{VC}}$,是 $\mathcal{H}$ 能够打散的最大训练样本数量 $n$。
物理意义:VC 维衡量了一个机器学习模型内在的“绝对复杂度”或“容量”。$d_{\text{VC}}$ 越大,模型越复杂,越容易拟合训练数据(但也更容易陷入过拟合)。
如果你想证明某个模型 $\mathcal{H}$ 的 VC 维恰好等于常数 $d$(即公式 $d_{\text{VC}}(\mathcal{H}) = d$),你必须同时证明以下两个条件,缺一不可:
条件一(证明下界):$d_{\text{VC}}(\mathcal{H}) \geq d$
你需要证明什么:存在 (there exists) 一个大小为 $d$ 的数据集 $S$,它可以被 $\mathcal{H}$ 打散。
解读:你不需要证明所有 $d$ 个点的组合都能被打散,你只需要在空间中巧妙地摆放一组 $d$ 个点(比如前面例子中把 3 个点摆成三角形),证明模型能完美分类这组点的所有 $2^d$ 种标签组合即可。
条件二(证明上界):$d_{\text{VC}}(\mathcal{H}) < d + 1$
你需要证明什么:每一个/任意一个 (every) 大小为 $d + 1$ 的数据集,都不能被 $\mathcal{H}$ 打散。
解读:这一步通常难得多。你必须证明无论别人怎么刁钻地摆放这 $d+1$ 个点,模型都绝对无法产生全部的 $2^{d+1}$ 种分类结果(就像前面例子中,无论 4 个点怎么摆,二维直线最多只能产生 14 种对分,永远达不到 16 种,所以二维直线的 VC 维小于 4)。
Sauer引理
如果增长函数 $m_{\mathcal{H}}(n)$ 总是等于 $2^n$,那就得不出有意义的泛化界限。Sauer 引理的伟大之处在于它证明了:只要 VC 维 $d_{\text{VC}}$ 是有限的,当样本量 $n$ 变大时,增长函数会被限制在一个多项式级别,而不再是指数级增长。
公式:设 $d_{\text{VC}}$ 为假设空间 $\mathcal{H}$ 的 VC 维,那么:
$$m_{\mathcal{H}}(n) \leq \sum_{i=0}^{d_{\text{VC}}} \binom{n}{i} \leq n^{d_{\text{VC}}} + 1$$
公式解读:增长函数 $m_{\mathcal{H}}(n)$ 的上界被限制为前面 $d_{\text{VC}}$ 项的组合数之和。为了方便后续计算,它又被进一步粗略放缩为一个更简单的多项式上界:$n^{d_{\text{VC}}} + 1$。
有了 Sauer 引理作铺垫,我们可以用用 VC 维来限制经验 Rademacher 复杂度。
公式:对于任意包含 $n$ 个样本的数据集 $S = {(\mathbf{x}_1, \dots, \mathbf{x}_n)}$,我们有:
$$\text{R}S(\mathcal{H}) \lesssim \left( \frac{d{\text{VC}} \log n}{n} \right)^{\frac{1}{2}}$$
公式解读:符号 $\lesssim$ 表示“渐进小于或约等于”(忽略掉一些常数项)。这个公式极其重要,它说明 Rademacher 复杂度大概以 $\mathcal{O}\left(\sqrt{\frac{d_{\text{VC}} \log n}{n}}\right)$ 的速度随样本量 $n$ 的增加而衰减。模型越复杂($d_{\text{VC}}$ 越大),复杂度越高;数据越多($n$ 越大),复杂度趋于 0。
覆盖数 (Covering Numbers)
首先,定义一个实值函数族 $\mathcal{F}$。这个集合中的每个函数都接收来自输入空间 $\mathcal{Z}$ 的输入,并输出实数。
由于函数在整个空间上可能无限复杂,我们将其行为限制(投影)在一个包含 $n$ 个样本的具体数据集 $S$ 上。
投影的具体数学表示为: $${(f(z_1), f(z_2), \dots, f(z_n)) : f \in \mathcal{F}}$$
这意味着,对于函数族 $\mathcal{F}$ 中的任意一个函数 $f$,我们只看它在这 $n$ 个数据点上的输出,从而将其转化为一个 $n$ 维向量。整个函数族就被表示为了这些向量的集合。
假设我们有一个由 $m$ 个函数组成的有限集合 ${f^{(1)}, \dots, f^{(m)}}$,要想让它成为原函数族 $\mathcal{F}$ 在数据集 $S$ 和 $L_p$ 范数下的 $\epsilon$-覆盖,必须满足以下公式 (12):
$$\sup_{f \in \mathcal{F}} \min_{j \in [m]} \left( \frac{1}{n} \sum_{i=1}^n |f(z_i) - f^{(j)}(z_i)|^p \right)^{\frac{1}{p}} \leq \epsilon \quad (12)$$
公式解读:
括号内的部分以及外面的指数 $\frac{1}{p}$ (公式下方标注了
distance w.r.t. ||·||_p),表示的是任意函数 $f$ 与覆盖集中的某个函数 $f^{(j)}$ 在数据集 $S$ 上的 $L_p$ 距离。$\min_{j \in [m]}$ 表示对于任意一个 $f$,我们在覆盖集中找到离它最近的那个代表函数 $f^{(j)}$。
$\sup_{f \in \mathcal{F}}$ 表示在整个函数族 $\mathcal{F}$ 中寻找最极端(最难被覆盖)的那个函数。
整体含义是:即使是函数族 $\mathcal{F}$ 中最边缘的函数,它与覆盖集中离它最近的代表函数之间的距离,也不能超过 $\epsilon$。
$\epsilon$-覆盖可以有很多个(比如包含大量函数的集合)。而覆盖数 $\mathcal{N}$ 定义为:能够构成 $\epsilon$-覆盖的最小集合的大小(即最小的基数 $m$)。它反映了用半径为 $\epsilon$ 的球去覆盖整个函数族,最少需要多少个球。
一般的 $L_p$ 距离:
$$d_p(f, g) = \left( \frac{1}{n} \sum_{i=1}^n |f(z_i) - g(z_i)|^p \right)^{\frac{1}{p}}$$
当 $p = 2$ 时 (类似于欧氏距离):
$$p = 2: \quad d_2(f, g) = \left( \frac{1}{n} \sum_{i=1}^n |f(z_i) - g(z_i)|^2 \right)^{\frac{1}{2}}$$
当 $p = \infty$ 时 (最大距离/切比雪夫距离): 表示在数据集 $S$ 上,两个函数差值的绝对值的最大值。
$$p = \infty: \quad d_\infty(f, g) = \max_{i \in [n]} |f(z_i) - g(z_i)|$$
覆盖数的作用和计算思路:
衡量函数空间的容量:覆盖数通过计算“需要多少个规定精度的球才能近似覆盖整个函数空间”,来衡量这个函数空间的大小或复杂度(Capacity)。
降维/投影:在实际操作中,为了处理无限维的函数空间,我们首先将这些函数投影到一个具体的样本集 $S$ 上。这样,原本抽象的函数就被转换成了 $\mathbb{R}^n$ 空间($n$维实数空间)中的一组向量。
使用范数度量:投影到向量空间后,我们就可以方便地使用 $L_p$ 范数(比如上一页提到的欧氏距离或最大值距离)来度量这个向量集合的容量。
如何估计一维利普希茨 (Lipschitz) 函数族的覆盖数 (Covering Number)
它证明了在一个限定的区间内,如果函数的坡度(变化率)被限制了,那么我们大概需要多少个“模板函数”就能以 $\epsilon$ 的误差覆盖所有可能的函数。
设定条件:令 $\mathcal{F}$ 为从 $[0, 1]$ 映射到 $[0, 1]$ 的所有 $G$-Lipschitz 函数的集合。也就是说,自变量和因变量都在 0 到 1 之间,且函数的最大斜率绝对值不超过 $G$。
核心结论公式: $$\log \mathcal{N}(\epsilon, \mathcal{F}, d_\infty) \lesssim G/\epsilon$$
- 公式解读:在最大距离度量 $d_\infty$(即各点误差的最大值)下,该函数族的 $\epsilon$-覆盖数的对数(通常称为度量熵 Metric Entropy),其上界近似受到 $G/\epsilon$ 的限制(符号 $\lesssim$ 表示渐进小于或忽略常数项/低阶项后的小于)。这说明函数的利普希茨常数 $G$ 越大,或者我们要求的精度 $\epsilon$ 越小(越精细),所需的覆盖数就呈指数级增长(因为左边取了对数)。
维数灾难 (Curse of Dimensionality)
$d$ 维利普希茨函数族定义
设定条件:令 $\mathcal{F}_d$ 为所有从 $[0, 1]^d$ 映射到 $[0, 1]$ 的 $G$-Lipschitz 函数的集合。
含义:这里的核心变化是输入空间从一维的区间 $[0, 1]$ 变成了 $d$ 维的超立方体 $[0, 1]^d$。函数的输入现在是一个包含 $d$ 个特征的向量,而输出依然是一个 0 到 1 之间的实数。函数的最大“坡度”(梯度范数)依然被限制为 $G$。
$$\log \mathcal{N}(\epsilon, \mathcal{F}, d_\infty) \lesssim G^d / \epsilon^d$$
_(注:公式中的 $\mathcal{F}$ 即指代前面定义的 $\mathcal{F}_d$)_
- 与一维的对比:回忆前一页,一维时的估计是 $\lesssim G/\epsilon$。现在到了 $d$ 维,等号右边变成了 $(G/\epsilon)^d$。
公式表明,为了在最大距离度量 $d_\infty$ 下以 $\epsilon$ 的精度覆盖这个 $d$ 维函数族,所需的对数覆盖数(度量熵)随着空间维度 $d$ 的增加呈指数级爆炸。
如果我们想把误差 $\epsilon$ 缩小一半(要求更精细的覆盖),在一维空间中,覆盖数只需增加相应的倍数;但在 $d$ 维空间中,所需的覆盖数将乘以 $2^d$。这意味着在高维特征空间中,函数族的复杂度(容量)大得惊人,如果不施加额外的强假设(比如稀疏性),仅仅依靠 Lipschitz 连续性,我们将需要海量的数据才能进行有效的学习(即控制泛化误差),这就是经典的“维数灾难”。