
Goroutine
Goroutine是一个轻量级的独立任务执行单元。
想象一下你是一个项目经理(主程序 main 函数),你有很多任务需要完成。
- 传统方式(没有并发): 你必须亲力亲为,做完任务A,才能开始任务B,再开始任务C。效率很低。
- 传统多线程方式: 你可以雇佣几个全职员工(操作系统线程)。每个员工都很能干,但雇佣和管理他们(创建、销毁、切换)的成本很高,比如要给他们配独立的办公室、电脑等(独立的内存堆栈,系统资源开销大)。你雇不了太多员工。
- Go 协程方式: 你雇佣了一个总管(Go 运行时),然后你只需要把任务写在小纸条上,交给总管。总管手下有一群临时工(Goroutines),他们非常轻量,只需要一张小板凳就能坐下干活(内存占用极小,通常只有几 KB)。你下达一个指令
go doSomething(),总管就会派一个临时工去做。成千上万个临时工对他来说都不是问题,管理成本极低。
创建 Goroutine 的语法非常简单,就是在普通的函数调用前加上一个 go 关键字。
- 假设你的代码是
go f(calculateX())。calculateX()这个函数会在当前的 Goroutine(也就是调用go的那个 Goroutine)中被立即执行,然后把它的返回值传递给新的 Goroutine 去执行f。函数f本身的逻辑,会在一个新的、独立的执行流中并发执行,不会阻塞当前的 Goroutine。
举个例子:
package main
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 3; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("world") // 启动一个新的 Goroutine 执行 say("world")
say("hello") // 在当前的 Goroutine (main) 中执行 say("hello")
}
输出可能会是:
hello
world
hello
world
hello
world
会看到 "hello" 和 "world" 交替打印,这证明了 say("hello") 和 say("world") 是在同时运行的。主程序(mainGoroutine)在启动了 say("world") 这个新的 Goroutine 后,并没有等待它结束,而是立刻继续执行下一行代码 say("hello")。
- 所有Goroutine 在相同的地址空间中运行,因此在访问共享的内存时必须进行同步。这意味着所有 Goroutine 都可以访问和修改同一个变量。如果两个或更多的 Goroutine 同时去修改同一个变量,结果将是不可预料的。
- Go 提供的传统同步工具包是
sync包,最常用的是sync.Mutex(互斥锁)。不过 Go 也有更好的方法,即通过通信来共享内存,而不是通过共享内存来通信。
信道(channel)
无缓冲信道
Goroutine 是并行的任务执行者,Channel 是这些执行者之间沟通的“桥梁”或“管道”。
- 信道是带有类型的管道。创建时必须指定类型,如
make(chan int)或make(chan string)。这保证了从管道里取出的东西和你放进去的东西类型一致,非常安全。操作符<-:ch <- v:把变量v发送到 信道ch中。箭头方向可以理解为数据v流向ch。v := <-ch:从 信道ch中接收一个值,并赋给变量v。箭头方向可以理解为数据从ch流出。
- 和映射与切片一样,信道在使用前必须创建。
- Channel 是一种引用类型,它的零值是
nil。一个nil的 channel 是无法使用的,发送和接收操作会永久阻塞。所以必须使用make函数来创建一个可用的 channel。 - 创建必须使用
ch := make(chan T)
- Channel 是一种引用类型,它的零值是
- 默认情况下,发送和接收操作在另一端准备好之前都会阻塞。
- 发送阻塞:
ch <- 100这行代码会暂停,直到有另一个 Goroutine 准备好执行<-ch。 - 接收阻塞:
value := <-ch这行代码会暂停,直到有另一个 Goroutine 准备好执行ch <- ...。 - 因为Channel有阻塞等待机制,所以不需要加任何的互斥锁。
- 发送阻塞:
示例代码:
package main
import "fmt"
// sum 函数计算一个切片中所有元素的和,
// 并将结果发送到信道 c 中。
func sum(s []int, c chan int) {
total := 0
for _, v := range s {
total += v
}
c <- total // 将计算结果发送到信道 c
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
// 创建一个用于通信的 int 类型信道
c := make(chan int)
// 将任务切分,启动两个 Goroutine 并发计算
// 第一个 Goroutine 计算前半部分
go sum(s[:len(s)/2], c)
// 第二个 Goroutine 计算后半部分
go sum(s[len(s)/2:], c)
// 在 main Goroutine 中等待并接收两个 Goroutine 的计算结果
// 第一次接收
x := <-c
// 第二次接收
y := <-c
// 此时 x 和 y 已经分别从两个 Goroutine 拿到了部分和
fmt.Println(x, y, x+y)
}
main函数创建了切片s和信道c。go sum(s[:len(s)/2], c)启动第一个 Goroutine,它开始计算[7, 2, 8]的和(结果是 17)。go sum(s[len(s)/2:], c)启动第二个 Goroutine,它开始计算[-9, 4, 0]的和(结果是 -5)。main函数继续向下执行,遇到x := <-c。此时,main函数会阻塞在这里,直到某个sumGoroutine 完成计算并通过c <- total发送结果过来。- 假设第一个 Goroutine 先算完,执行
c <- 17。这个操作正好和main函数的x := <-c配对成功!main接收到 17 并赋值给x,main的阻塞解除。 main函数继续执行下一行y := <-c。它会再次阻塞,等待第二个结果。- 此时,第二个 Goroutine 也算完了,执行
c <- -5。这个操作和main的y := <-c配对成功!main接收到 -5 并赋值给y,阻塞再次解除。 main函数已经收到了所有需要的结果,继续执行fmt.Println,最终打印出17 -5 12。
需要注意的是,这是无缓冲信道。特点是如果上面有任意一个 sum 已经计算完了,但是还没有到接收的位置,那么向 c 的 sum 传递就会被阻塞。因为发送和接收操作在另一端准备好之前都会阻塞。
带缓冲信道
信道可以是 带缓冲的。缓冲长度可以作为第二个参数提供给 make 来初始化。此时,仅当信道的缓冲区填满后,向其发送数据时才会阻塞。而当当缓冲区为空时,接受方会阻塞。
缓冲信道最经典的应用场景之一就是任务分发(Worker Pool)。老板(main)快速分派一堆任务,员工们(Workers)按照自己的节奏来领取和处理。
package main
import (
"fmt"
"time"
)
// worker 是一个“员工”Goroutine。它会不断从 jobs 信道领取任务,
// 完成后将结果可以发送到另一个信道(本例中为打印)。
func worker(id int, jobs <-chan int) {
// for...range 会自动从信道接收数据,直到信道被关闭
for j := range jobs {
fmt.Printf("员工 %d 开始处理任务 %d\n", id, j)
time.Sleep(time.Second) // 模拟处理任务需要1秒
fmt.Printf("员工 %d 完成了任务 %d\n", id, j)
}
}
func main() {
const numJobs = 5
// 创建一个容量为 5 的缓冲信道来存放任务
jobs := make(chan int, numJobs)
// 启动 3 个员工 Goroutine,他们都准备从 jobs 信道接收任务
for w := 1; w <= 3; w++ {
go worker(w, jobs)
}
// 老板(main)一次性快速分派 5 个任务
fmt.Println("老板开始分派任务...")
for j := 1; j <= numJobs; j++ {
jobs <- j
fmt.Printf("任务 %d 已分派\n", j)
}
// 所有任务都分派完了,关闭 jobs 信道。
// 关闭信道是一个明确的信号,告诉接收方(员工们)不会再有新任务了。
close(jobs)
fmt.Println("所有任务都已分派完毕。")
// 等待所有员工完成工作 (在实际程序中,需要用 WaitGroup 等待)
// 这里我们简单地睡一会儿,以确保能看到所有输出
time.Sleep(3 * time.Second)
fmt.Println("所有任务处理完成。")
}
缓冲信道引入了一个队列(缓冲区),允许发送和接收操作在一定程度上异步进行。
信道的关闭
- 发送者可通过
close关闭一个信道来表示没有需要发送的值了。close(ch)是一个明确的信号,由发送方发出,告诉所有接收方:“这个信道不会再有新的值被发送进来了”。 - 接受者只能检查信道是否关闭:
v, ok := <-ch语法,这个语法会返回两个值:
v: 从信道接收到的值。ok(布尔值):true: 表示成功从信道接收到了一个值v。false: 表示信道已经被关闭,并且里面没有任何值了。此时v会是该类型的零值(如int的0,string的"")。
for {
v, ok := <-ch
if !ok { // 如果 ok 是 false,说明牌子挂出来了
fmt.Println("信道关闭了,退出循环。")
break // 退出循环
}
fmt.Println("接收到值:", v)
}
for i := range c,这个循环在内部帮我们自动完成了v, ok的检查和break逻辑。它会:- 持续从信道
c中接收值,并赋值给i。 - 一旦信道
c被关闭且缓冲区为空,这个循环就会自动、正常地结束。
- 持续从信道
需要注意的是:只应由发送者关闭信道,而不应由接收者关闭。向一个已经关闭的信道发送数据会引发程序 panic。
信道与文件不同,通常情况下无需关闭它们。因为 Go 的信道是由垃圾回收器管理的,即使不关闭,只要它不再被使用,内存也会被回收。关闭信道是一种通信信号,而不是一种资源管理。它的主要目的就是为了通知下游的接收者(尤其是使用 for...range 的接收者)可以停止等待了。
package main
import "fmt"
// fibonacci 是发送者(生产者)
// 它计算 n 个斐波那契数,并通过信道 c 发送出去
func fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x // 发送一个数
x, y = y, x+y
}
// 所有数都发送完毕后,由发送者关闭信道
close(c)
}
func main() {
// 创建一个容量为 10 的缓冲信道
c := make(chan int, 10)
// 启动一个 Goroutine 来生产数据
// 我们要计算 10 个数,正好和容量相等
go fibonacci(cap(c), c)
// main 是接收者(消费者)
// 使用 for...range 循环来接收数据
// 这个循环会一直运行,直到 fibonacci Goroutine 关闭了信道 c
for i := range c {
fmt.Println(i)
}
fmt.Println("循环结束,程序退出。")
}
方向信道
普通的信道声明:
ch := make(chan int)
这种信道是双向的。这意味着可以对它进行两种操作:
- 发送数据到信道:
ch <- 10 - 接收信道的数据:
value := <-ch
方向信道,就是限制了数据流动的方向。它是一种类型约束,能增强程序的类型安全,让代码的意图更清晰。
a) <-chan int (只接收 Receive-Only)
- 语法解读:
<-箭头在chan关键字的左边。你可以把它想象成数据从信道流出 (<-chan)。 - 含义: 声明这是一个只用于接收数据的信道。
- 限制:
- 可以做:
value := <-jobs(接收数据) - 不能做:
jobs <- 123(尝试发送数据会导致编译错误)
- 可以做:
比如,jobs <-chan int 意味着 worker 函数只能从 jobs 这个信道里读取任务,它不能往里面添加新任务。这非常合理,因为“工人”的职责是完成任务,而不是创造任务。
b) chan<- int (只发送 Send-Only)
- 语法解读:
<-箭头在chan关键字的右边。你可以把它想象成数据流入信道 (chan<-)。 - 含义: 声明这是一个只用于发送数据的信道。
- 限制:
- 可以做:
results <- 999(发送数据) - 不能做:
value := <-results(尝试接收数据会导致编译错误)
- 可以做:
比如,results chan<- int 意味着 worker 函数只能向 results 这个信道里写入结果,它不能从中读取结果。这也非常合理,“工人”完成工作后是“上报”结果,而不是去“索要”别人的结果。
向信道就像一个契约。当你的函数声明了参数是方向信道时,它就在向调用者和编译器做出承诺:
“我保证,对于jobs这个信道,我只会从中读取数据。对于results这个信道,我只会向里面写入数据。”
这样做有两大好处:
- 防止误用:它可以在编译阶段就帮你发现逻辑错误。比如,如果你在
worker函数里不小心写了jobs <- 1这样的代码,编译器会立刻报错,告诉你违反了信道方向的规定。这避免了在程序运行时出现难以排查的 bug。 - 代码自文档化:任何阅读这个函数声明的人,都能立刻明白数据是如何在这个函数中流动的,大大增强了代码的可读性。看到
jobs <-chan int就知道这是输入,看到results chan<- int就知道这是输出。
需要注意的是,不能用 make 直接创建一个方向信道。总是需要先创建一个普通的双向信道,然后 Go 语言允许你将它赋值或传递给一个需要单向信道的函数。
package main
import "fmt"
// pinger 只向信道发送消息
func pinger(pings chan<- string, msg string) {
fmt.Println("Pinger: sending message...")
pings <- msg
// value := <-pings // 这行代码会导致编译错误!
}
// ponger 只从信道接收消息
func ponger(pongs <-chan string) {
msg := <-pongs
fmt.Println("Ponger: received message:", msg)
// pongs <- "another message" // 这行代码也会导致编译错误!
}
func main() {
// 1. 创建一个普通的、双向的信道
ch := make(chan string, 1)
// 2. 当把 ch 传递给 pinger 时,它在 pinger 函数内部被当作一个“只发送”信道
pinger(ch, "hello world")
// 3. 当把 ch 传递给 ponger 时,它在 ponger 函数内部被当作一个“只接收”信道
ponger(ch)
}
例子中,ch 本身是双向的,但在 pinger 函数的作用域内,它只能被用来发送;在 ponger 的作用域内,它只能被用来接收。Go 的类型系统保证了这个约束。
select 语句
select 语句使一个 Go 程可以等待多个通信操作。
- “通信操作”指的就是对信道(Channel)的发送 (
ch <- v) 或接收 (<-ch)。 select的核心价值就是“多路复用”,使能同时处理多个信道,而不是一次只能处理一个。select语句的结构和switch很像,它包含多个case,每个case都是一个信道操作。- 只要所有的
case都无法立即执行(比如接收的信道是空的,或者发送的信道是满的),整个select语句就会暂停(阻塞)。 - 一旦其中任何一个
case的条件满足了(比如一个空信道接收到了数据),select就会解除阻塞,并执行那个case内部的代码。
当多个分支都准备好时,select 会随机选择一个执行。这是 select 的一个重要特性,用于保证公平性,防止“饥饿”。如果 select 总是按从上到下的顺序检查,那么写在前面的 case 就会有更高的优先级,这在很多并发场景下是不希望看到的。随机选择确保了每个准备好的信道都有均等的机会被处理。
select 可以带有 default 分支。带有 default 分支的 select 语句,核心行为变成了 “立即检查”。它会这样工作:
- 在
select语句执行的那一瞬间,立即检查所有的case是否准备就绪。 - 如果 至少有一个
case准备好了(例如,信道c里正好有数据),就随机选择一个执行,不执行default。 - 如果 所有的
case在那一瞬间都没有准备好(例如,信道c是空的,接收会阻塞),那么立即执行default分支,整个select语句不会有任何等待。
select 最常见的用途有三个:多路监听、实现超时、非阻塞操作。
多路监听
package main
import (
"fmt"
"time"
)
func main() {
c1 := make(chan string)
c2 := make(chan string)
// Goroutine 1: 1秒后向 c1 发送消息
go func() {
time.Sleep(1 * time.Second)
c1 <- "来自 c1 的消息"
}()
// Goroutine 2: 2秒后向 c2 发送消息
go func() {
time.Sleep(2 * time.Second)
c2 <- "来自 c2 的消息"
}()
// 使用 for 循环两次,以接收来自两个信道的消息
for i := 0; i < 2; i++ {
// select 会在这里阻塞,直到 c1 或 c2 中有一个接收到数据
select {
case msg1 := <-c1:
fmt.Println("接收到:", msg1)
case msg2 := <-c2:
fmt.Println("接收到:", msg2)
}
}
}
输出:
接收到: 来自 c1 的消息
接收到: 来自 c2 的消息
程序会先阻塞在 select,1秒后 c1 就绪,打印第一条消息。然后进入下一次循环,再次阻塞,再过1秒后 c2 就绪,打印第二条消息。
实现超时
package main
import (
"fmt"
"time"
)
func main() {
c1 := make(chan string, 1)
// 模拟一个耗时3秒的操作
go func() {
time.Sleep(3 * time.Second)
c1 <- "操作结果"
}()
select {
case res := <-c1:
fmt.Println(res)
// time.After 会在指定时间后向一个信道发送当前时间,正好可以用于 select
case <-time.After(2 * time.Second):
fmt.Println("操作超时!")
}
}
输出:
操作超时!
在这个例子中,select 同时监听 c1 和一个 2 秒的定时器。因为定时器在 2 秒后就绪,而 c1 需要 3 秒,所以定时器的 case 会先被执行,程序打印超时信息。
非阻塞操作
我们可以实现非阻塞的接收和发送
想象一个游戏循环,你需要在每一帧都检查玩家是否有新的输入。你不能因为等待玩家输入而让整个游戏画面卡住。
package main
import (
"fmt"
"time"
)
func main() {
playerInput := make(chan string)
// 模拟玩家在2秒后才输入
go func() {
time.Sleep(2 * time.Second)
playerInput <- "JUMP"
}()
ticker := time.NewTicker(500 * time.Millisecond) // 每秒渲染两帧
defer ticker.Stop()
for i := 0; i < 6; i++ {
<-ticker.C // 等待下一帧的时间点
select {
case input := <-playerInput:
fmt.Println("处理玩家输入:", input)
// 在这里可以执行跳跃逻辑
default:
// 在这一帧,玩家没有输入
fmt.Println("渲染游戏画面... (无新输入)")
}
}
}
输出:
渲染游戏画面... (无新输入)
渲染游戏画面... (无新输入)
渲染游戏画面... (无新输入)
渲染游戏画面... (无新输入)
处理玩家输入: JUMP
渲染游戏画面... (无新输入)
在这个例子里,游戏循环不会因为等待 playerInput 而卡住。在玩家输入之前,每一帧都会执行 default 分支,保证了画面的流畅渲染。
- 非阻塞发送
有时候你想发送一个值,但如果接收方还没准备好(比如缓冲区满了),你不想等待,而是想直接放弃这次发送。
场景: 假设你在写一个日志系统。主程序产生日志的速度非常快,而后端处理日志的速度比较慢。你不希望因为日志系统处理不过来,而把整个主程序给阻塞住。在这种情况下,宁愿丢弃一些日志,也要保证主程序的正常运行。
package main
import (
"fmt"
"time"
)
func main() {
// 创建一个容量很小的日志缓冲
logChannel := make(chan string, 2)
// 模拟一个慢速的日志消费者
go func() {
// 每秒处理一条日志
for log := range logChannel {
time.Sleep(1 * time.Second)
fmt.Println("日志已记录:", log)
}
}()
// 模拟主程序快速产生5条日志
for i := 1; i <= 5; i++ {
msg := fmt.Sprintf("日志消息 #%d", i)
select {
case logChannel <- msg:
fmt.Println("成功发送日志:", msg)
default:
// 当 logChannel 的缓冲区满了,发送会阻塞,
// 于是 default 分支会被执行。
fmt.Println("!!! 日志缓冲区已满,丢弃日志:", msg)
}
time.Sleep(100 * time.Millisecond) // 模拟主程序做其他事
}
close(logChannel)
time.Sleep(3 * time.Second) // 等待消费者处理完
}
输出可能如下:
成功发送日志: 日志消息 #1
成功发送日志: 日志消息 #2
!!! 日志缓冲区已满,丢弃日志: 日志消息 #3
!!! 日志缓冲区已满,丢弃日志: 日志消息 #4
!!! 日志缓冲区已满,丢弃日志: 日志消息 #5
日志已记录: 日志消息 #1
日志已记录: 日志消息 #2
可以看到,当缓冲区(容量为2)被前两条消息占满后,后续的发送操作都失败了,程序立即执行了 default 分支,丢弃了日志,而主程序本身并没有被阻塞。
空接收与空发送
在 go 中,如果我们只关心发送和接收这个阻塞的行为,而非实际传送的数据的时候,我们可以使用空接收和空发送。
空接收 (<-ch)
它是一种忽略结果的行为。你在代码中明确表示:“我需要等待这个信道上的一个信号才能继续,但我对信号附带的数据(值)不感兴趣。” 它的本质是利用副作用(阻塞)来进行同步。
“空”发送 (ch <- struct{}{})
它是一种发送无信息实体的行为。因为发送操作在逻辑上必须传递一个东西,所以 我们可以选择了一个最理想的“东西”:一个零内存占用的空结构体 struct{}{}。这既满足了语法要求,又在事实上没有传递任何数据,完美地实现了“纯信号发送”的目标。
package main
import (
"fmt"
"time"
)
// worker 的 done 信道类型是 chan struct{}
func worker(done chan struct{}) {
fmt.Print("后台任务正在执行...")
time.Sleep(2 * time.Second)
fmt.Println("完成!")
// 任务完成后,发送一个“零字节”的信号
// struct{}{} 是空结构体类型的一个实例(值)
done <- struct{}{}
}
func main() {
// 创建一个用于传递“空结构体”信号的信道
done := make(chan struct{})
go worker(done)
// 使用“空接收”来等待信号
// 阻塞在这里,直到 worker 发送了空结构体信号
<-done
fmt.Println("主程序收到完成信号,可以退出了。")
}
练习:等价二叉查找树
不同二叉树的叶节点上可以保存相同的值序列。例如,以下两个二叉树都保存了序列 1,1,2,3,5,8,13。
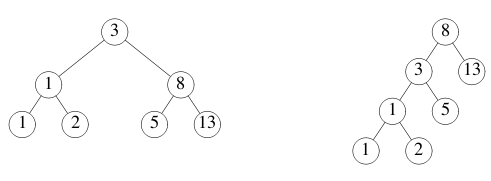
在大多数语言中,检查两个二叉树是否保存了相同序列的函数都相当复杂。 我们将使用 Go 的并发和信道来编写一个简单的解法。
本例使用了 tree 包,它定义了类型:
type Tree struct {
Left *Tree
Value int
Right *Tree
}
这个问题的核心是“比较两个二叉树中的值序列是否相等”,而不是比较它们的结构。
- 如何从树中提取值序列? 对于一个二叉查找树(Binary Search Tree),要得到一个有序的序列,我们需要使用中序遍历(In-order Traversal)。遍历规则是:先遍历左子树,然后访问根节点,最后遍历右子树。
- 如何解决这个问题? 我们可以把问题分解成两个独立的角色:Goroutine 和 Channel 是实现这种模式的完美工具。我们可以为每棵树启动一个
WalkGoroutine(生产者),让它们分别把值发送到各自的 Channel 中。然后,Same函数(消费者)就可以同时从这两个 Channel 中接收值进行比较。- 生产者 (Producer):负责遍历一棵树,并把遍历得到的值按顺序“生产”出来。这就是
Walk函数要做的事。 - 消费者/比较者 (Consumer/Comparer):负责从两个生产者那里,一步一步地获取值,并进行比较。这就是
Same函数要做的事。
- 生产者 (Producer):负责遍历一棵树,并把遍历得到的值按顺序“生产”出来。这就是
Walk 函数需要对树进行中序遍历,并将每个节点的值发送到信道 ch。一个常见的实现方式是使用递归。
为了能在所有值都发送完毕后通知接收者,我们必须在遍历结束后关闭信道。一个好的实践是创建一个递归的辅助函数,然后在主函数中调用它,并在调用结束后关闭信道。
// walkRecursive 是一个递归辅助函数,用于执行中序遍历
func walkRecursive(t *tree.Tree, ch chan int) {
// 如果节点为空,则直接返回
if t == nil {
return
}
// 1. 遍历左子树
walkRecursive(t.Left, ch)
// 2. 发送根节点的值
ch <- t.Value
// 3. 遍历右子树
walkRecursive(t.Right, ch)
}
// Walk 遍历树 t,并将树中所有的值发送到信道 ch。
// 遍历结束后,它会关闭信道。
func Walk(t *tree.Tree, ch chan int) {
walkRecursive(t, ch)
// 所有值都已发送完毕,关闭信道作为完成信号
close(ch)
}
Same 函数是问题的核心。它需要创建两个信道,为两棵树分别启动一个 Walk Goroutine,然后同时从两个信道接收值进行比较。
// Same 判断 t1 和 t2 是否包含相同的值。
func Same(t1, t2 *tree.Tree) bool {
ch1 := make(chan int)
ch2 := make(chan int)
// 并发地遍历两棵树
go Walk(t1, ch1)
go Walk(t2, ch2)
// 循环比较来自两个信道的值
for {
// 同时从两个信道接收值
// 使用 ", ok" 语法来检查信道是否已经关闭
v1, ok1 := <-ch1
v2, ok2 := <-ch2
// 检查值是否相等
if v1 != v2 {
return false
}
// 检查两个信道是否同时关闭
// 如果一个关闭了,另一个没关闭,说明序列长度不同
if ok1 != ok2 {
return false
}
// 如果两个信道都已关闭 (ok1 为 false),
// 说明我们已经成功比较完了所有值,它们都相等。
if !ok1 {
break // 退出循环
}
}
// 如果循环正常结束,说明两棵树相等
return true
}
所有代码和 main 函数中的测试逻辑组合在一起。
package main
import (
"fmt"
"golang.org/x/tour/tree"
)
// walkRecursive 是一个递归辅助函数,用于执行中序遍历
func walkRecursive(t *tree.Tree, ch chan int) {
if t == nil {
return
}
walkRecursive(t.Left, ch)
ch <- t.Value
walkRecursive(t.Right, ch)
}
// Walk 遍历树 t,并将树中所有的值发送到信道 ch。
// 遍历结束后,它会关闭信道。
func Walk(t *tree.Tree, ch chan int) {
walkRecursive(t, ch)
close(ch)
}
// Same 判断 t1 和 t2 是否包含相同的值。
func Same(t1, t2 *tree.Tree) bool {
ch1 := make(chan int)
ch2 := make(chan int)
// 并发地遍历两棵树
go Walk(t1, ch1)
go Walk(t2, ch2)
// 循环比较来自两个信道的值
for {
v1, ok1 := <-ch1
v2, ok2 := <-ch2
// 如果值不同,或者一个信道关闭而另一个没有,则树不相同
if v1 != v2 || ok1 != ok2 {
return false
}
// 如果两个信道都关闭了,说明已成功比较完所有值
if !ok1 {
break
}
}
return true
}
func main() {
// --- 测试 Walk 函数 ---
fmt.Println("测试 Walk 函数 (tree.New(1)):")
ch := make(chan int)
go Walk(tree.New(1), ch)
// 使用 for...range 循环从信道接收值,直到信道被关闭
for v := range ch {
fmt.Print(v, " ")
}
fmt.Println("\n")
// --- 测试 Same 函数 ---
fmt.Println("测试 Same 函数:")
// 测试两棵包含相同值的树
result1 := Same(tree.New(1), tree.New(1))
fmt.Printf("Same(tree.New(1), tree.New(1)) 应该返回 true, 实际返回: %v\n", result1)
// 测试两棵包含不同值的树
result2 := Same(tree.New(1), tree.New(2))
fmt.Printf("Same(tree.New(1), tree.New(2)) 应该返回 false, 实际返回: %v\n", result2)
}
代码输出:
测试 Walk 函数 (tree.New(1)):
1 2 3 4 5 6 7 8 9 10
测试 Same 函数:
Same(tree.New(1), tree.New(1)) 应该返回 true, 实际返回: true
Same(tree.New(1), tree.New(2)) 应该返回 false, 实际返回: false
最终解释: 这个并发解决方案的优雅之处在于,它将遍历(数据生成)和比较(数据消费)完全解耦了。
Walk 函数只关心如何正确地遍历树,而 Same 函数只关心如何正确地比较两个数据流。
它们通过信道这个“管道”连接起来,各自独立工作,代码清晰且易于理解,完美地体现了 Go 的并发哲学:“不要通过共享内存来通信,而要通过通信来共享内存。”
互斥锁
互斥锁 sync.Mutex 是 Go 语言中除了信道(Channel)之外的另一种并发控制工具。信道用于在 Goroutine 之间传递数据和同步,而互斥锁则用于保护共享资源,确保独占访问。
有这样一个场景:
你有一个银行账户,余额是 1000 元。现在你和你家人同时用两部手机给这个账户转账。
- 你发起一笔“存入 200 元”的交易。
- 几乎在同一瞬间,你的家人发起一笔“存入 500 元”的交易。
如果系统没有保护机制,可能会发生以下情况(这被称为数据竞争 Race Condition):
- 你的手机程序读取了余额:
1000。 - 家人的手机程序也读取了余额:
1000。 - 你的手机程序计算新余额:
1000 + 200 = 1200。 - 家人的手机程序计算新余额:
1000 + 500 = 1500。 - 你的手机程序将
1200写回账户。 - 家人的手机程序将
1500写回账户。
最终余额是 1500,而不是正确的 1700。你的 200 元存款“消失”了!
为了解决这个问题,我们需要一种机制,确保“读取-计算-写入”这一整套操作在同一时间只能由一个人(一个 Goroutine)完成。这就是互斥(Mutual Exclusion),而实现这个机制的工具就是互斥锁(Mutex)。
Mutex 相当于一把房间的钥匙,而那个共享的变量(比如银行账户余额)就在这个房间里。
Lock()方法: 相当“拿钥匙,锁门”。- 当一个 Goroutine 调用
m.Lock()时,它会去拿钥匙。 - 如果钥匙在墙上(没人占用),它就拿到钥匙,锁上门,然后进入房间执行操作。
- 如果它发现钥匙已经被别人拿走了(另一个 Goroutine 已经调用了
Lock()),它就必须在门外排队等待(阻塞),直到里面的人出来。
- 当一个 Goroutine 调用
Unlock()方法: 相当于“开门,还钥匙”。- 当 Goroutine 完成了在房间里的所有操作后,它必须调用
m.Unlock()。 - 这个动作会把门打开,并把钥匙放回墙上,这样在外面排队的下一个人(Goroutine)就可以拿到钥匙,进入房间。
- 当 Goroutine 完成了在房间里的所有操作后,它必须调用
关键点:因为只有一把钥匙,所以永远保证了房间里最多只有一个人。这就确保了对共享变量的访问是互斥的、安全的。
一个具体的 SafeCounter 例子,它安全地实现了一个并发计数器。
package main
import (
"fmt"
"sync"
"time"
)
// SafeCounter 是一个并发安全的计数器
type SafeCounter struct {
mu sync.Mutex // 互斥锁,保护下面的 v
v map[string]int
}
// Inc 方法:增加给定 key 的计数值
func (c *SafeCounter) Inc(key string) {
c.mu.Lock() // 获取钥匙,锁门
// 在锁的保护下,安全地修改 map
c.v[key]++
c.mu.Unlock() // 释放钥匙,开门
}
// Value 方法:获取给定 key 的当前计数值
func (c *SafeCounter) Value(key string) int {
c.mu.Lock() // 获取钥匙,锁门
// defer 语句确保在函数返回时,一定会执行 Unlock 操作
defer c.mu.Unlock()
// 在锁的保护下,安全地读取 map
return c.v[key]
}
func main() {
c := SafeCounter{v: make(map[string]int)}
for i := 0; i < 1000; i++ {
// 启动1000个Goroutine并发地调用Inc方法
go c.Inc("somekey")
}
// 等待所有Goroutine完成(这里用Sleep简化,实际应用中会用WaitGroup)
time.Sleep(time.Second)
// 安全地读取最终值
fmt.Println(c.Value("somekey")) // 输出:1000
}
在 Value 方法中,我们使用了 defer c.mu.Unlock()。这是一个在 Go 中使用 Mutex 的最佳实践。
defer 关键字会确保在函数返回之前,它后面的语句一定会被执行。
好处
- 防止忘记解锁:将
Lock和defer Unlock写在一起,可以从视觉上保证不会忘记解锁。 - 处理多返回路径:如果函数中间有多个
return语句,不需要在每个return前都写一遍c.mu.Unlock()。defer会帮你处理好。 - 处理程序崩溃 (Panic):如果
Lock和Unlock之间的代码发生了panic,程序会异常终止。如果没有defer,Unlock就永远不会被调用,锁就永远不会被释放,所有其他等待这个锁的 Goroutine 都会永久阻塞,造成死锁。而defer语句即使在发生panic时也保证会被执行,所以锁一定会被释放。
这里需要多说的是,看似好像第三点中程序既然都崩溃了,那么不需要处理异常,但是需要注意,在 Go 语言中,panic 不一定等于“程序崩溃”。
在 Go 中,panic 是一种程序控制流,类似于其他语言中的“抛出异常”。它首先会在当前的 Goroutine 中发生。当一个 Goroutine 发生 panic 时,它会:
- 立即停止执行当前函数的剩余代码。
- 开始执行当前函数中所有被
defer的语句。 - 执行完
defer后,函数返回到其调用者。 - 这个过程在调用栈中不断向上“冒泡”,每一层函数的
defer都会被执行。
这个“冒泡”过程会一直持续,直到到达该 Goroutine 的最顶层。如果在这个过程中的任何一层,有一个 defer 语句调用了内置的 recover() 函数,那么这个 panic 就会被“捕获”,程序的控制流会恢复正常,并且其他 Goroutine 不会受到影响,程序会继续运行。
只有当一个 panic 在其 Goroutine 中一路“冒泡”到顶层都没有被 recover() 捕获时,它才会导致整个程序的崩溃。所以需要进行 defer。
练习:Web 爬虫
我们将会使用 Go 的并发特性来并行化一个 Web 爬虫。
修改 Crawl 函数来并行地抓取 URL,并且保证不重复。
提示: 可以用一个 map 来缓存已经获取的 URL,但是要注意 map 本身并不是并发安全的
package main
import (
"fmt"
)
type Fetcher interface {
// Fetch 返回 URL 所指向页面的 body 内容,
// 并将该页面上找到的所有 URL 放到一个切片中。
Fetch(url string) (body string, urls []string, err error)
}
// Crawl 用 fetcher 从某个 URL 开始递归的爬取页面,直到达到最大深度。
func Crawl(url string, depth int, fetcher Fetcher) {
// TODO: 并行地爬取 URL。
// TODO: 不重复爬取页面。
// 下面并没有实现上面两种情况:
if depth <= 0 {
return
}
body, urls, err := fetcher.Fetch(url)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("found: %s %q\n", url, body)
for _, u := range urls {
Crawl(u, depth-1, fetcher)
}
return
}
func main() {
Crawl("https://golang.org/", 4, fetcher)
}
// fakeFetcher 是待填充结果的 Fetcher。
type fakeFetcher map[string]*fakeResult
type fakeResult struct {
body string
urls []string
}
func (f fakeFetcher) Fetch(url string) (string, []string, error) {
if res, ok := f[url]; ok {
return res.body, res.urls, nil
}
return "", nil, fmt.Errorf("not found: %s", url)
}
// fetcher 是填充后的 fakeFetcher。
var fetcher = fakeFetcher{
"https://golang.org/": &fakeResult{
"The Go Programming Language",
[]string{
"https://golang.org/pkg/",
"https://golang.org/cmd/",
},
},
"https://golang.org/pkg/": &fakeResult{
"Packages",
[]string{
"https://golang.org/",
"https://golang.org/cmd/",
"https://golang.org/pkg/fmt/",
"https://golang.org/pkg/os/",
},
},
"https://golang.org/pkg/fmt/": &fakeResult{
"Package fmt",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
"https://golang.org/pkg/os/": &fakeResult{
"Package os",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
}
原始的 Crawl 函数是一个简单的递归函数,它一个接一个地串行爬取 URL。我们需要把它改造成并行的。
- 当
fetcher.Fetch(url)返回多个 URL 时,我们应该为每个新的 URL 启动一个独立的 Goroutine 去处理,而不是在一个循环里等待它们逐个完成。 - 同时,我们需要一个地方记录所有已经访问过或正在访问的 URL。一个
map[string]bool是很自然的选择。如果一个 URL 已经在这个 map 里,我们就跳过它。 - 由于会有多个 Goroutine 同时检查和更新这个共享的
map,我们必须对其进行保护,否则就会发生数据竞争。sync.Mutex(互斥锁) 是保护它的选择。 main函数在启动第一个CrawlGoroutine 后不能立即退出,它需要等待所有衍生的爬取任务全部结束。sync.WaitGroup是专门用来解决“等待一组 Goroutine 完成”这个问题的标准工具。
架构:
- 创建一个结构体来统一管理共享状态,这个结构体包含用于去重的
map和保护它的Mutex。 - 改造
Crawl函数,让它接收这个共享状态的指针和一个sync.WaitGroup的指针。 - 在
Crawl函数内部:- 首先用
WaitGroup标记任务的开始和结束。 - 在访问共享的
map之前加锁,访问之后解锁。 - 检查 URL 是否已被爬取,如果已爬取则直接返回。
- 如果没有,标记为已爬取,然后执行
Fetch。 - 对于
Fetch返回的新 URL,启动新的CrawlGoroutine,并正确更新WaitGroup的计数。
- 首先用
- 在
main函数中,初始化共享状态和WaitGroup,启动第一个爬取任务,然后等待所有任务完成。
代码实现:
package main
import (
"fmt"
"sync"
)
// SafeVisited 结构体用于安全地存储已访问的 URL。
// 它包含一个互斥锁和一个 map。
type SafeVisited struct {
mu sync.Mutex
visited map[string]bool
}
// CheckAndSet 检查一个 URL 是否已被访问。
// 如果没有,它会将该 URL 标记为已访问并返回 true。
// 如果已经访问过,它返回 false。
// 这个操作是原子性的,因为被互斥锁保护。
func (v *SafeVisited) CheckAndSet(url string) bool {
v.mu.Lock()
defer v.mu.Unlock()
if v.visited[url] {
return false // 已经访问过,返回 false 表示不应继续爬取
}
v.visited[url] = true
return true // 第一次访问,返回 true 表示应该继续爬取
}
type Fetcher interface {
// Fetch 返回 URL 所指向页面的 body 内容,
// 并将该页面上找到的所有 URL 放到一个切片中。
Fetch(url string) (body string, urls []string, err error)
}
// Crawl 用 fetcher 从某个 URL 开始递归的爬取页面,直到达到最大深度。
// 它现在是并发安全的,并且会避免重复爬取。
func Crawl(url string, depth int, fetcher Fetcher, visited *SafeVisited, wg *sync.WaitGroup) {
// 在函数退出时,通知 WaitGroup 当前 Goroutine 已完成任务
defer wg.Done()
// 如果深度小于等于0,或者 URL 已被访问,则不再继续
if depth <= 0 {
return
}
// 检查并设置 URL 为已访问。如果 CheckAndSet 返回 false,
// 说明另一个 Goroutine 已经或正在处理这个 URL,所以当前 Goroutine 可以直接返回。
if !visited.CheckAndSet(url) {
return
}
// 执行爬取
body, urls, err := fetcher.Fetch(url)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("found: %s %q\n", url, body)
// 为找到的每个新 URL 启动一个新的 Crawl Goroutine
for _, u := range urls {
wg.Add(1) // 在启动 Goroutine 之前,增加 WaitGroup 的计数
go Crawl(u, depth-1, fetcher, visited, wg)
}
return
}
func main() {
// 创建 WaitGroup 和共享的 visited 状态
var wg sync.WaitGroup
visited := &SafeVisited{visited: make(map[string]bool)}
// 初始 URL
startURL := "https://golang.org/"
// WaitGroup 的初始计数为 1,因为我们即将启动第一个任务
wg.Add(1)
// 启动并发爬虫
go Crawl(startURL, 4, fetcher, visited, &wg)
// 等待所有爬取任务完成
// Wait 会阻塞,直到 WaitGroup 的计数器变回 0
wg.Wait()
fmt.Println("爬取完成!")
}
// --- 下面的代码是练习提供的,无需修改 ---
// fakeFetcher 是待填充结果的 Fetcher。
type fakeFetcher map[string]*fakeResult
type fakeResult struct {
body string
urls []string
}
func (f fakeFetcher) Fetch(url string) (string, []string, error) {
if res, ok := f[url]; ok {
return res.body, res.urls, nil
}
return "", nil, fmt.Errorf("not found: %s", url)
}
// fetcher 是填充后的 fakeFetcher。
var fetcher = fakeFetcher{
"https://golang.org/": &fakeResult{
"The Go Programming Language",
[]string{
"https://golang.org/pkg/",
"https://golang.org/cmd/",
},
},
"https://golang.org/pkg/": &fakeResult{
"Packages",
[]string{
"https://golang.org/",
"https://golang.org/cmd/",
"https://golang.org/pkg/fmt/",
"https://golang.org/pkg/os/",
},
},
"https://golang.org/pkg/fmt/": &fakeResult{
"Package fmt",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
"https://golang.org/pkg/os/": &fakeResult{
"Package os",
[]string{
"https://golang.org/",
"https://golang.org/pkg/",
},
},
}
这里需要注意的是,sync.WaitGroup 是 Go 标准库中的一个同步工具,它的作用就像一个“并发任务计数器”。它允许一个 Goroutine (通常是 main Goroutine) 等待一组其他 Goroutine 全部执行完毕。
WaitGroup 只有三个核心方法:
Add(delta int): 增加计数- 每当你要启动一个新的 Goroutine 去执行任务时,就调用
wg.Add(1),表示计数器加一。
- 每当你要启动一个新的 Goroutine 去执行任务时,就调用
Done(): 减少计数- 在每个 Goroutine 完成其任务的最后,必须调用
wg.Done(),表示计数器减一。wg.Done()实际上是wg.Add(-1)的一个便捷写法。通常我们会使用defer wg.Done()来确保它一定会被执行。
- 在每个 Goroutine 完成其任务的最后,必须调用
Wait(): 等待计数器归零- 这个方法会阻塞当前的 Goroutine,直到
WaitGroup的内部计数器减少到 0。一旦计数器为 0,等待就会解除,程序继续向下执行。
- 这个方法会阻塞当前的 Goroutine,直到
一个简单的使用模式:
package main
import (
"fmt"
"sync"
"time"
)
func worker(id int, wg *sync.WaitGroup) {
// 在函数退出时,通知 WaitGroup 任务已完成
defer wg.Done()
fmt.Printf("员工 %d 开始工作\n", id)
time.Sleep(time.Second) // 模拟工作耗时
fmt.Printf("员工 %d 完成工作\n", id)
}
func main() {
// 1. 创建一个 WaitGroup 实例
var wg sync.WaitGroup
// 2. 启动 3 个员工 Goroutine
for i := 1; i <= 3; i++ {
// 每次启动前,都先把计数器加 1
wg.Add(1)
go worker(i, &wg)
}
fmt.Println("经理:所有任务已分派,等待员工完成...")
// 3. 等待所有 Goroutine 完成(等待计数器归零)
wg.Wait()
fmt.Println("经理:所有员工都已完成工作,可以下班了。")
}
所以在这里需要注意的是我们解法中 main 函数里的 wg.Add(1): 在 go 关键字之前调用 wg.Add(1) 至关重要。这可以防止一种极端情况:main 函数在最后一个 Goroutine 启动并执行 Add(1) 之前就检查 Wait(),导致提前退出。
为了理解这一点,我们来看一下错误的写法,即把 wg.Add(1) 放在 Goroutine 内部:
// 错误写法的示例
func main() {
var wg sync.WaitGroup
for i := 1; i <= 3; i++ {
// 错误:在 Goroutine 内部增加计数
go func(id int) {
wg.Add(1) // <--- 错误的位置!
defer wg.Done()
fmt.Printf("员工 %d 开始工作\n", id)
}(i)
}
wg.Wait() // <--- 危险!
fmt.Println("经理可能在员工还没领任务时就下班了。")
}
可能发生的“极端情况”:
mainGoroutine 进入for循环。- 它非常快地启动了 3 个新的 Goroutine。因为
go是非阻塞的,所以这个for循环可能在几微秒内就执行完了。 mainGoroutine 立刻执行到wg.Wait()这一行。- 关键点:此时,
WaitGroup的计数器仍然是 0!因为那 3 个新的员工 Goroutine 可能还没有被 Go 的调度器分配到 CPU 时间去执行,所以它们内部的wg.Add(1)根本还没来得及运行。 wg.Wait()检查计数器,发现是 0,于是它认为“没有任务需要等待”,就立即返回,根本不会阻塞。main函数继续执行,打印 "经理可能...下班了",然后程序退出。- 整个程序可能在任何一个
workerGoroutine 打印“开始工作”之前就已经结束了。
代码解释
SafeVisited结构体:- 我们将
map和sync.Mutex封装在一起,这是一个很好的实践,使得状态管理更清晰。 CheckAndSet方法将“检查”和“设置”两个动作合并成一个原子操作。这是避免竞态条件的关键:如果分开检查和设置,可能有两个 Goroutine 同时检查发现某个 URL 未被访问,然后两个都去爬取,这就重复了。
- 我们将
Crawl函数的变化:- 参数: 增加了
visited *SafeVisited和wg *sync.WaitGroup,用于接收共享状态和同步工具。 defer wg.Done(): 这是WaitGroup的标准用法。确保无论函数从哪个路径退出(正常返回、深度耗尽、URL已访问),都会调用Done()来减少计数,防止main函数永久等待。- 并发启动: 在
for循环中,我们不再是递归调用Crawl(...),而是使用go Crawl(...)来启动一个新的 Goroutine。 wg.Add(1): 在go关键字之前调用wg.Add(1)至关重要。这可以防止一种极端情况:main函数在最后一个 Goroutine 启动并执行Add(1)之前就检查Wait(),导致提前退出。
- 参数: 增加了
main函数的变化:main函数现在扮演了“总指挥”的角色。- 它负责初始化所有需要共享的东西(
visited和wg)。 - 它负责启动第一个任务 (
go Crawl(...))。 - 它负责等待所有任务(包括所有衍生的子任务)完成 (
wg.Wait())。